检索与重排
在语义搜索中,我们展示了如何使用 SentenceTransformer 为查询、句子和段落计算嵌入,以及如何将其用于语义搜索。对于复杂的搜索任务,例如问答检索,通过使用 检索与重排序 可以显著改进搜索。
检索与重排序管道
以下用于信息检索/问答检索的管道效果非常好。所有组件都在本文中提供和解释
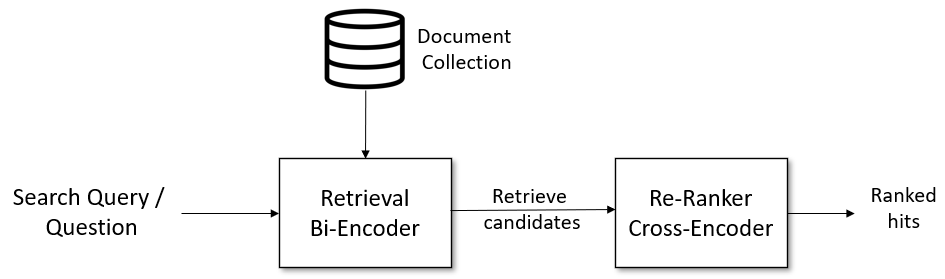
给定一个搜索查询,我们首先使用一个检索系统,它检索一个包含例如100个可能命中项的大列表,这些命中项可能与查询相关。对于检索,我们可以使用词汇搜索(例如使用像 Elasticsearch 这样的向量引擎),或者我们可以使用带有 SentenceTransformer(又名双编码器)的密集检索。然而,检索系统可能会检索到与搜索查询不太相关的文档。因此,在第二阶段,我们使用基于 CrossEncoder 的重排序器,它对所有候选文档针对给定搜索查询的相关性进行评分。输出将是一个排名列表,我们可以将其呈现给用户。
检索:双编码器
为了检索候选集,我们可以使用词汇搜索(例如 Elasticsearch),或者我们可以使用 Sentence Transformers 中实现的双编码器。
词汇搜索会在您的文档集合中查找查询词的字面匹配。它不会识别同义词、缩写或拼写变体。相反,语义搜索(或密集检索)将搜索查询编码到向量空间中,并检索在向量空间中接近的文档嵌入。
语义搜索克服了词汇搜索的缺点,可以识别同义词和缩写。请查看语义搜索文章以了解实现语义搜索的不同选项。
重排序器:交叉编码器
检索器必须对包含数百万条目的大型文档集合高效。然而,它可能会返回不相关的候选文档。基于交叉编码器的重排序器可以显著改善用户的最终结果。查询和可能的文档同时传递给Transformer网络,然后该网络输出一个介于0和1之间的分数,表示该文档与给定查询的相关程度。
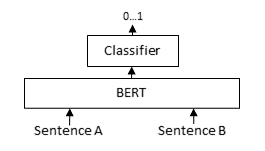
交叉编码器的优势在于性能更高,因为它们在查询和文档之间执行注意力。对数千或数百万个(查询,文档)对进行评分会相当慢。因此,我们使用检索器创建一组例如100个可能的候选文档,然后由交叉编码器对其进行重排序。
示例脚本
retrieve_rerank_simple_wikipedia.ipynb [ Colab 版本 ]:此脚本使用较小的 简易英语维基百科 作为文档集合,为用户问题/搜索查询提供答案。首先,我们将所有维基百科文章拆分为段落,并使用双编码器对其进行编码。如果输入新的查询/问题,它会由相同的双编码器进行编码,并检索具有最高余弦相似度的段落(参见语义搜索)。接下来,由交叉编码器重排序器对检索到的候选文档进行评分,并将交叉编码器得分最高的5个段落呈现给用户。
in_document_search_crossencoder.py:如果您只有少量段落,我们不执行检索阶段。例如,当您想在单个文档中执行搜索时,就是这种情况。在此示例中,我们以关于欧洲的维基百科文章为例,并将其拆分为段落。然后,使用交叉编码器重排序器对搜索查询/问题和所有段落进行评分。返回与查询最相关的段落。
预训练双编码器(检索)
双编码器独立地为您的段落和您的搜索查询生成嵌入。您可以这样使用它
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("multi-qa-mpnet-base-dot-v1")
docs = [
"My first paragraph. That contains information",
"Python is a programming language.",
]
document_embeddings = model.encode(docs)
query = "What is Python?"
query_embedding = model.encode(query)
有关如何比较嵌入的更多详细信息,请参阅语义搜索。
我们提供基于以下内容的预训练模型
MS MARCO: 来自 Bing 搜索引擎的 50万个真实用户查询。参见 MS MARCO 模型
预训练交叉编码器(重排序器)
有关预训练交叉编码器模型,请参阅:MS MARCO 交叉编码器