加速推理
Sentence Transformers 支持 3 种后端来计算嵌入,每种后端都有自己的优化,以加快推理速度
PyTorch
PyTorch 后端是 Sentence Transformers 的默认后端。如果您不指定设备,它将使用“cuda”、“mps”和“cpu”中可用的最强选项。其默认用法如下所示
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
如果您正在使用 GPU,可以使用以下选项来加速推理:
Float32 (fp32,全精度) 是 torch 中的默认浮点格式,而 float16 (fp16,半精度) 是一种降低精度的浮点格式,可以在最小模型精度损失的情况下加速 GPU 上的推理。要使用它,您可以在初始化期间指定 torch_dtype,或者在初始化模型上调用 model.half()。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2", model_kwargs={"torch_dtype": "float16"})
# or: model.half()
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
Bfloat16 (bf16) 类似于 fp16,但保留了更多 fp32 的原始精度。要使用它,您可以在初始化期间指定 torch_dtype,或者在初始化模型上调用 model.bfloat16()。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2", model_kwargs={"torch_dtype": "bfloat16"})
# or: model.bfloat16()
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
ONNX
ONNX 可以通过将模型转换为 ONNX 格式并使用 ONNX Runtime 运行模型来加速推理。要使用 ONNX 后端,您必须安装带有 onnx 或 onnx-gpu 额外依赖项的 Sentence Transformers,分别用于 CPU 或 GPU 加速。
pip install sentence-transformers[onnx-gpu]
# or
pip install sentence-transformers[onnx]
要将模型转换为 ONNX 格式,您可以使用以下代码:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2", backend="onnx")
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
如果模型路径或仓库中已包含 ONNX 格式的模型,Sentence Transformers 会自动使用它。否则,它会将模型转换为 ONNX 格式。
注意
如果您希望在 Sentence Transformers 之外使用 ONNX 模型,您将需要自己执行池化和/或归一化。ONNX 导出仅转换 Transformer 组件,该组件输出词元嵌入,而不是句子嵌入。要获取句子嵌入,您需要应用适当的池化策略(如平均池化)以及原始模型使用的任何归一化。
通过 model_kwargs 传递的所有关键字参数都将传递给 ORTModel.from_pretrained。一些值得注意的参数包括
provider: 用于加载模型的 ONNX Runtime 提供程序,例如"CPUExecutionProvider"。有关可能的提供程序,请参阅 https://runtime.onnx.org.cn/docs/execution-providers/。如果未指定,将使用最强的提供程序(例如"CUDAExecutionProvider")。file_name: 要加载的 ONNX 文件的名称。如果未指定,将默认为"model.onnx",否则为"onnx/model.onnx"。此参数对于指定优化或量化模型很有用。export: 一个布尔标志,指定是否导出模型。如果未提供,如果模型仓库或目录中尚未包含 ONNX 模型,则export将设置为True。
提示
强烈建议保存导出的模型,以避免每次运行代码时都必须重新导出。如果您的模型是本地的,您可以通过调用 model.save_pretrained() 来实现
model = SentenceTransformer("path/to/my/model", backend="onnx")
model.save_pretrained("path/to/my/model")
或者如果您的模型来自 Hugging Face Hub,则使用 model.push_to_hub()
model = SentenceTransformer("intfloat/multilingual-e5-small", backend="onnx")
model.push_to_hub("intfloat/multilingual-e5-small", create_pr=True)
优化 ONNX 模型
ONNX 模型可以使用 Optimum 进行优化,从而在 CPU 和 GPU 上都能加速。为此,您可以使用 export_optimized_onnx_model() 函数,该函数将优化后的模型保存在您指定的目录或模型仓库中。它期望:
model: 一个使用 ONNX 后端加载的 Sentence Transformer、Sparse Encoder 或 Cross Encoder 模型。optimization_config:"O1"、"O2"、"O3"或"O4",表示来自AutoOptimizationConfig的优化级别,或一个OptimizationConfig实例。model_name_or_path: 用于保存优化后模型文件的路径,或者如果您想将其推送到 Hugging Face Hub,则为仓库名称。push_to_hub: (可选)一个布尔值,用于将优化后的模型推送到 Hugging Face Hub。create_pr: (可选)一个布尔值,用于在推送到 Hugging Face Hub 时创建一个拉取请求(pull request)。当您没有仓库的写权限时很有用。file_suffix: (可选) 保存模型时要附加到模型名称的字符串。如果未指定,将使用优化级别名称字符串,如果优化配置不是字符串优化级别,则只使用"optimized"。
请参阅此示例,了解如何使用 优化级别 3 (基本和扩展通用优化、transformers 特定的融合、快速 Gelu 近似) 导出模型。
仅优化一次
from sentence_transformers import SentenceTransformer, export_optimized_onnx_model
model = SentenceTransformer("all-MiniLM-L6-v2", backend="onnx")
export_optimized_onnx_model(
model=model,
optimization_config="O3",
model_name_or_path="sentence-transformers/all-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
在拉取请求合并之前
from sentence_transformers import SentenceTransformer
pull_request_nr = 2 # TODO: Update this to the number of your pull request
model = SentenceTransformer(
"all-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
revision=f"refs/pr/{pull_request_nr}"
)
拉取请求合并后
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"all-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
)
仅优化一次
from sentence_transformers import SentenceTransformer, export_optimized_onnx_model
model = SentenceTransformer("path/to/my/mpnet-legal-finetuned", backend="onnx")
export_optimized_onnx_model(
model=model, optimization_config="O3", model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
优化后
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"path/to/my/mpnet-legal-finetuned",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
)
量化 ONNX 模型
ONNX 模型可以使用 Optimum 量化为 int8 精度,从而加快 CPU 上的推理速度。为此,您可以使用 export_dynamic_quantized_onnx_model() 函数,该函数将量化后的模型保存在您指定的目录或模型仓库中。与静态量化不同,动态量化不需要校准数据集。它期望:
model: 一个使用 ONNX 后端加载的 Sentence Transformer、Sparse Encoder 或 Cross Encoder 模型。quantization_config:"arm64"、"avx2"、"avx512"或"avx512_vnni",表示来自AutoQuantizationConfig的量化配置,或一个QuantizationConfig实例。model_name_or_path: 用于保存量化后模型文件的路径,或者如果您想将其推送到 Hugging Face Hub,则为仓库名称。push_to_hub: (可选)一个布尔值,用于将量化后的模型推送到 Hugging Face Hub。create_pr: (可选)一个布尔值,用于在推送到 Hugging Face Hub 时创建一个拉取请求(pull request)。当您没有仓库的写权限时很有用。file_suffix: (可选) 保存模型时要附加到模型名称的字符串。如果未指定,将使用"qint8_quantized"。
在我的 CPU 上,每个默认量化配置("arm64"、"avx2"、"avx512"、"avx512_vnni")都产生了大致相同的加速效果。
请参阅此示例,了解如何将模型量化为 int8 并使用 avx512_vnni。
仅量化一次
from sentence_transformers import SentenceTransformer, export_dynamic_quantized_onnx_model
model = SentenceTransformer("all-MiniLM-L6-v2", backend="onnx")
export_dynamic_quantized_onnx_model(
model=model,
quantization_config="avx512_vnni",
model_name_or_path="sentence-transformers/all-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
在拉取请求合并之前
from sentence_transformers import SentenceTransformer
pull_request_nr = 2 # TODO: Update this to the number of your pull request
model = SentenceTransformer(
"all-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
revision=f"refs/pr/{pull_request_nr}",
)
拉取请求合并后
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"all-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
)
仅量化一次
from sentence_transformers import SentenceTransformer, export_dynamic_quantized_onnx_model
model = SentenceTransformer("path/to/my/mpnet-legal-finetuned", backend="onnx")
export_dynamic_quantized_onnx_model(
model=model, quantization_config="avx512_vnni", model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
量化后
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"path/to/my/mpnet-legal-finetuned",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
)
OpenVINO
OpenVINO 通过将模型导出为 OpenVINO 格式,可以在 CPU 上加速推理。要使用 OpenVINO 后端,您必须安装带有 openvino 额外依赖项的 Sentence Transformers。
pip install sentence-transformers[openvino]
要将模型转换为 OpenVINO 格式,您可以使用以下代码:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2", backend="openvino")
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
如果模型路径或仓库中已包含 OpenVINO 格式的模型,Sentence Transformers 会自动使用它。否则,它会将模型转换为 OpenVINO 格式。
注意
如果您希望在 Sentence Transformers 之外使用 OpenVINO 模型,您将需要自己执行池化和/或归一化。OpenVINO 导出仅转换 Transformer 组件,该组件输出词元嵌入,而不是句子嵌入。要获取句子嵌入,您需要应用适当的池化策略(如平均池化)以及原始模型使用的任何归一化。
model_kwargs 传递的关键字参数都将传递给 OVBaseModel.from_pretrained()。一些值得注意的参数包括:file_name: 要加载的 ONNX 文件的名称。如果未指定,将默认为"openvino_model.xml",否则为"openvino/openvino_model.xml"。此参数对于指定优化或量化模型很有用。export: 一个布尔标志,指定是否导出模型。如果未提供,如果模型仓库或目录中尚未包含 OpenVINO 模型,则export将设置为True。
提示
强烈建议保存导出的模型,以避免每次运行代码时都必须重新导出。如果您的模型是本地的,您可以通过调用 model.save_pretrained() 来实现
model = SentenceTransformer("path/to/my/model", backend="openvino")
model.save_pretrained("path/to/my/model")
或者如果您的模型来自 Hugging Face Hub,则使用 model.push_to_hub()
model = SentenceTransformer("intfloat/multilingual-e5-small", backend="openvino")
model.push_to_hub("intfloat/multilingual-e5-small", create_pr=True)
量化 OpenVINO 模型
OpenVINO 模型可以使用 Optimum Intel 量化为 int8 精度,以加快推理速度。为此,您可以使用 export_static_quantized_openvino_model() 函数,该函数将量化模型保存在您指定的目录或模型仓库中。训练后静态量化期望:
model: 一个使用 OpenVINO 后端加载的 Sentence Transformer、Sparse Encoder 或 Cross Encoder 模型。quantization_config: (可选) 量化配置。此参数接受以下任一选项:None表示默认的 8 位量化,一个表示量化配置的字典,或一个OVQuantizationConfig实例。model_name_or_path: 用于保存量化后模型文件的路径,或者如果您想将其推送到 Hugging Face Hub,则为仓库名称。dataset_name: (可选) 用于校准的加载数据集的名称。如果未指定,则默认为glue数据集中的sst2子集。dataset_config_name: (可选)要加载的数据集的具体配置。dataset_split: (可选)要加载的数据集划分(例如,‘train’、‘test’)。column_name: (可选)数据集中用于校准的列名。push_to_hub: (可选)一个布尔值,用于将量化后的模型推送到 Hugging Face Hub。create_pr: (可选)一个布尔值,用于在推送到 Hugging Face Hub 时创建一个拉取请求(pull request)。当您没有仓库的写权限时很有用。file_suffix: (可选) 保存模型时要附加到模型名称的字符串。如果未指定,将使用"qint8_quantized"。
请参阅此示例,了解如何使用 静态量化 将模型量化为 int8。
仅量化一次
from sentence_transformers import SentenceTransformer, export_static_quantized_openvino_model
model = SentenceTransformer("all-MiniLM-L6-v2", backend="openvino")
export_static_quantized_openvino_model(
model=model,
quantization_config=None,
model_name_or_path="sentence-transformers/all-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
在拉取请求合并之前
from sentence_transformers import SentenceTransformer
pull_request_nr = 2 # TODO: Update this to the number of your pull request
model = SentenceTransformer(
"all-MiniLM-L6-v2",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
revision=f"refs/pr/{pull_request_nr}"
)
拉取请求合并后
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"all-MiniLM-L6-v2",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
仅量化一次
from sentence_transformers import SentenceTransformer, export_static_quantized_openvino_model
from optimum.intel import OVQuantizationConfig
model = SentenceTransformer("path/to/my/mpnet-legal-finetuned", backend="openvino")
quantization_config = OVQuantizationConfig()
export_static_quantized_openvino_model(
model=model, quantization_config=quantization_config, model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
量化后
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"path/to/my/mpnet-legal-finetuned",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
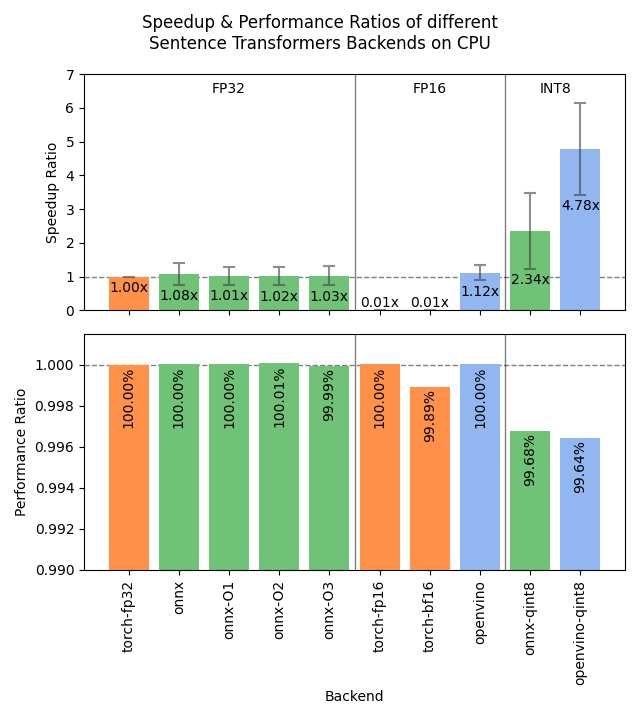
基准测试
以下图像显示了不同后端在 GPU 和 CPU 上的基准测试结果。结果是对 4 种不同大小的模型、3 个数据集和大量批量大小进行平均后得出的。
展开基准测试详情
加速比
- 硬件:RTX 3090 GPU, i7-17300K CPU
-
数据集:GPU 测试使用 2000 个样本,CPU 测试使用 1000 个样本。
- sentence-transformers/stsb: 平均 38.9 个字符 (SD=13.9)
- sentence-transformers/natural-questions: 仅答案,平均 619.6 个字符 (SD=345.3)
- stanfordnlp/imdb: 文本重复 4 次,平均 9589.3 个字符 (SD=633.4)
-
模型
- sentence-transformers/all-MiniLM-L6-v2: 22.7M 参数;批量大小为 16、32、64、128 和 256。
- BAAI/bge-base-en-v1.5: 109M 参数;批量大小为 16、32、64 和 128。
- mixedbread-ai/mxbai-embed-large-v1: 335M 参数;批量大小为 8、16、32 和 64。GPU 测试中还有 128 和 256。
- BAAI/bge-m3: 567M 参数;批量大小为 2、4。GPU 测试中还有 8、16 和 32。
-
评估
- 语义文本相似度:基于 sentence-transformers/stsb 测试集上的余弦相似度的 Spearman 秩相关,通过 EmbeddingSimilarityEvaluator 计算。
- 信息检索:基于 NanoBEIR 整个数据集集合上的余弦相似度的 NDCG@10,通过 InformationRetrievalEvaluator 计算。
-
后端
-
torch-fp32: PyTorch,使用 float32 精度(默认)。 -
torch-fp16: PyTorch,使用 float16 精度,通过model_kwargs={"torch_dtype": "float16"}实现。 -
torch-bf16: PyTorch,使用 bfloat16 精度,通过model_kwargs={"torch_dtype": "bfloat16"}实现。 -
onnx: ONNX,使用 float32 精度,通过backend="onnx"实现。 -
onnx-O1: ONNX,使用 float32 精度和 O1 优化,通过export_optimized_onnx_model(..., optimization_config="O1", ...)和backend="onnx"实现。 -
onnx-O2: ONNX,使用 float32 精度和 O2 优化,通过export_optimized_onnx_model(..., optimization_config="O2", ...)和backend="onnx"实现。 -
onnx-O3: ONNX,使用 float32 精度和 O3 优化,通过export_optimized_onnx_model(..., optimization_config="O3", ...)和backend="onnx"实现。 -
onnx-O4: ONNX,使用 float16 精度和 O4 优化,通过export_optimized_onnx_model(..., optimization_config="O4", ...)和backend="onnx"实现。 -
onnx-qint8: ONNX 量化为 int8,使用“avx512_vnni”,通过export_dynamic_quantized_onnx_model(..., quantization_config="avx512_vnni", ...)和backend="onnx"。不同的量化配置产生了大致相同的加速效果。 -
openvino: OpenVINO,通过backend="openvino"实现。 -
openvino-qint8: OpenVINO,量化到 int8,通过export_static_quantized_openvino_model(..., quantization_config=OVQuantizationConfig(), ...)和backend="openvino"实现。
-
对于 CPU,ONNX 在文本最短的 stsb 数据集上也更强:ONNX 为 1.39 倍,优于 OpenVINO 的 1.29 倍。使用 int8 量化的 ONNX 甚至更强,速度提升了 3.08 倍。对于较长的文本,ONNX 和 OpenVINO 甚至可能比 PyTorch 表现稍差,因此我们建议使用您的特定模型和数据测试不同的后端,以找到最适合您用例的后端。

建议
基于基准测试,以下流程图可以帮助您决定为您的模型使用哪种后端:
%%{init: {
"theme": "neutral",
"flowchart": {
"curve": "bumpY"
}
}}%%
graph TD
A(What is your hardware?) -->|GPU| B(Is your text usually smaller<br>than 500 characters?)
A -->|CPU| C(Is a 0.4% accuracy loss<br>acceptable?)
B -->|yes| D[onnx-O4]
B -->|no| F[float16]
C -->|yes| G[openvino-qint8]
C -->|no| H(Do you have an Intel CPU?)
H -->|yes| I[openvino]
H -->|no| J[onnx]
click D "#optimizing-onnx-models"
click F "#pytorch"
click G "#quantizing-openvino-models"
click I "#openvino"
click J "#onnx"
注意
您的实际效果可能会有所不同,您应该始终使用您的特定模型和数据来测试不同的后端,以找到最适合您用例的方案。
用户界面
此 Hugging Face Space 提供了一个用户界面,用于导出、优化和量化 ONNX 或 OpenVINO 模型