语义文本相似度
语义文本相似度(Semantic Textual Similarity, STS)为两个文本的相似度打分。在本例中,我们使用 stsb 数据集作为训练数据来微调一个 CrossEncoder 模型。请参阅以下示例脚本,了解如何基于 STS 数据来调整 CrossEncoder 模型。
training_stsbenchmark.py - 这个例子展示了如何从一个预训练的 Transformer 模型(例如
distilroberta-base)创建并微调一个 CrossEncoder 模型。
你也可以训练并使用 SentenceTransformer 模型来完成这个任务。更多细节,请参见Sentence Transformer > 训练示例 > 语义文本相似度。
训练数据
在 STS 中,我们有句子对以及一个表示其相似度的分数。在原始的 STSbenchmark 数据集中,分数范围是 0 到 5。我们在 stsb 中将这些分数归一化到 0 到 1 的范围,这是 BinaryCrossEntropyLoss 所需的,正如您在损失函数概览中所见。
以下是我们的训练数据的简化版本
from datasets import Dataset
sentence1_list = ["My first sentence", "Another pair"]
sentence2_list = ["My second sentence", "Unrelated sentence"]
labels_list = [0.8, 0.3]
train_dataset = Dataset.from_dict({
"sentence1": sentence1_list,
"sentence2": sentence2_list,
"label": labels_list,
})
# => Dataset({
# features: ['sentence1', 'sentence2', 'label'],
# num_rows: 2
# })
print(train_dataset[0])
# => {'sentence1': 'My first sentence', 'sentence2': 'My second sentence', 'label': 0.8}
print(train_dataset[1])
# => {'sentence1': 'Another pair', 'sentence2': 'Unrelated sentence', 'label': 0.3}
在上述脚本中,我们直接加载 stsb 数据集。
from datasets import load_dataset
train_dataset = load_dataset("sentence-transformers/stsb", split="train")
# => Dataset({
# features: ['sentence1', 'sentence2', 'score'],
# num_rows: 5749
# })
损失函数
我们使用 BinaryCrossEntropyLoss 作为我们的损失函数。
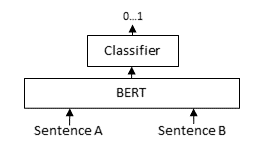
对于每个句子对,我们将句子 A 和句子 B 传入基于 BERT 的模型,之后一个分类器头将来自 BERT 模型的中间表示转换为一个相似度分数。通过这个损失函数,我们应用 torch.nn.BCEWithLogitsLoss,它接受 logits(也称为输出、原始预测值)和黄金标准相似度分数来计算一个损失,该损失表示模型在该批次上的表现如何。最小化这个损失可以提高模型的性能。
推理
您可以使用任何为 STS 预训练的 CrossEncoder 模型来执行推理,如下所示:
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/stsb-roberta-base")
scores = model.predict([("It's a wonderful day outside.", "It's so sunny today!"), ("It's a wonderful day outside.", "He drove to work earlier.")])
# => array([0.60443085, 0.00240758], dtype=float32)