Cross-Encoders
SentenceTransformers 也支持加载用于句子对评分和句子对分类任务的 Cross-Encoder。
Cross-Encoder vs. Bi-Encoder
首先,理解 Bi-Encoder 和 Cross-Encoder 之间的区别很重要。
Bi-Encoder 为给定的句子生成一个句子嵌入。我们将句子 A 和 B 独立地传递给 BERT,从而得到句子嵌入 u 和 v。然后可以使用余弦相似度来比较这些句子嵌入。
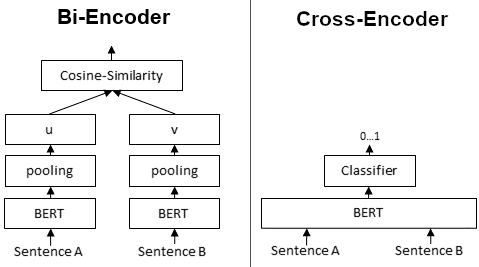
相反,对于 Cross-Encoder,我们将两个句子同时传递给 Transformer 网络。然后它会产生一个介于 0 和 1 之间的输出值,表示输入句子对的相似度。
Cross-Encoder 不会生成句子嵌入。而且,我们也不能将单个句子传递给 Cross-Encoder。
正如我们的论文中详细介绍的,Cross-Encoder 比 Bi-Encoder 性能更好。然而,对于许多应用来说,它们并不实用,因为它们不生成我们可以进行索引或使用余弦相似度高效比较的嵌入。
何时使用 Cross- / Bi-Encoder?
只要你有一组预定义的句子对需要评分,就可以使用 Cross-Encoder。例如,你有 100 个句子对,你想为这 100 个句子对获取相似度分数。
Bi-Encoder(请参阅计算句子嵌入)用于任何需要在向量空间中获得句子嵌入以便进行高效比较的场景。应用场景例如信息检索/语义搜索或聚类。对于这些应用,Cross-Encoder 会是错误的选择:使用 CrossEncoder 对 10,000 个句子进行聚类需要计算约 5000 万个句子组合的相似度分数,这大约需要 65 个小时。而使用 Bi-Encoder,你只需计算每个句子的嵌入,这仅需 5 秒钟。然后你就可以进行聚类了。
Cross-Encoder 的使用
使用 Cross-Encoder 非常简单:
from sentence_transformers.cross_encoder import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2")
scores = model.predict([["My first", "sentence pair"], ["Second text", "pair"]])
你向 model.predict 传递一个句子对列表。注意,Cross-Encoder 不处理单个句子,你必须传递句子对。
作为模型名称,你可以传递任何与 Hugging Face AutoModel 类兼容的模型或路径。
要查看一个完整的示例,即用一个查询来对语料库中所有可能的句子进行评分,请参阅 cross-encoder_usage.py。
结合 Bi-Encoder 和 Cross-Encoder
Cross-Encoder 的性能优于 Bi-Encoder,但是它们在处理大型数据集时扩展性不佳。在这种情况下,结合使用 Cross-Encoder 和 Bi-Encoder 可能是有意义的,例如在信息检索/语义搜索场景中:首先,你使用高效的 Bi-Encoder 为一个查询检索出例如前 100 个最相似的句子。然后,你使用 Cross-Encoder 通过计算每个(查询,命中结果)组合的分数来对这 100 个结果进行重排序。
有关结合 Bi-Encoder 和 Cross-Encoder 的更多详细信息,请参阅应用 - 信息检索。
训练 Cross-Encoders
请参阅Cross-Encoder 训练了解如何训练你自己的 Cross-Encoder 模型。