自然语言推断
给定两个句子(前提和假设),自然语言推断(NLI)任务是判断前提是否蕴含假设,两者是否矛盾,或者它们是否中立。常用的 NLI 数据集有 SNLI 和 MultiNLI。
Conneau 等人的研究表明,NLI 数据在训练句子嵌入方法时非常有用。我们在 Sentence-BERT 论文中也发现了这一点,并经常将 NLI 作为句子嵌入方法微调的第一步。
要使用 NLI 进行训练,请参阅以下示例文件
-
此示例使用了原始 [Sentence Transformers 论文](https://arxiv.org/abs/1908.10084) 中描述的
SoftmaxLoss。 -
在我们最初的 SBERT 论文中使用的
SoftmaxLoss并没有产生最佳性能。一个更好的损失函数是MultipleNegativesRankingLoss,在这种情况下,我们提供句子对或三元组。在此脚本中,我们提供格式为 (锚点, 蕴含句, 矛盾句) 的三元组。NLI 数据提供了这样的三元组。MultipleNegativesRankingLoss产生的性能远高于SoftmaxLoss,也更直观。我们在 《使用知识蒸馏使单语句子嵌入多语化》论文中使用了这种损失函数来训练转述模型。 -
遵循 GISTEmbed 论文,我们可以使用指导模型来修改
MultipleNegativesRankingLoss中的批内负样本选择。如果指导模型认为候选负样本对过于相似,则在训练期间会忽略该对。实际上,GISTEmbedLoss倾向于产生比MultipleNegativesRankingLoss更强的训练信号,但代价是在指导模型上运行推理会产生一些训练开销。
您也可以为此任务训练和使用 CrossEncoder 模型。有关更多详细信息,请参见交叉编码器 > 训练示例 > 自然语言推断。
数据
我们将 SNLI 和 MultiNLI 合并为一个名为 AllNLI 的数据集。这两个数据集包含句子对和三个标签之一:蕴含(entailment)、中立(neutral)、矛盾(contradiction)。
| 句子 A (前提) | 句子 B (假设) | 标签 |
|---|---|---|
| 一场有多个男性参与的足球比赛。 | 一些男人在进行一项运动。 | 蕴含 |
| 一个年长和一个年轻的男人在微笑。 | 两个男人在笑着看地板上玩的猫。 | 中立 |
| 一个男人在某个东亚国家检查一个人物的制服。 | 那个男人在睡觉。 | 矛盾 |
我们将 AllNLI 格式化为几个不同的子集,以兼容不同的损失函数。例如,请参见 AllNLI 的三元组子集。
SoftmaxLoss (Softmax 损失)
Conneau 等人描述了如何在一个孪生网络之上使用 softmax 分类器来学习有意义的句子表示。我们可以通过使用 SoftmaxLoss 来实现这一点。
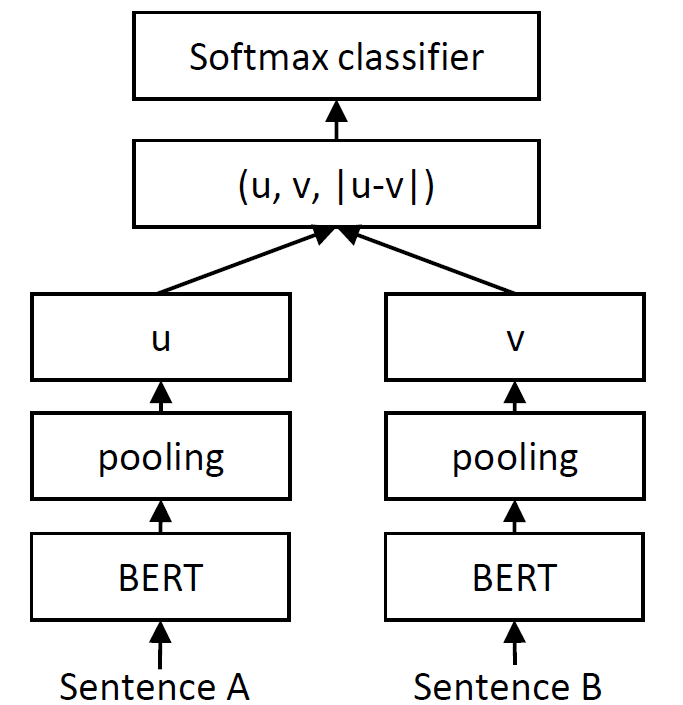
我们将两个句子通过我们的 SentenceTransformer 模型,得到句子嵌入 u 和 v。然后我们将 u、v 和 |u-v| 连接起来,形成一个长向量。这个向量随后被传递给一个 softmax 分类器,该分类器预测我们的三个类别(蕴含、中立、矛盾)。
这种设置可以学习到句子嵌入,这些嵌入以后可以用于各种任务。
MultipleNegativesRankingLoss (多负例排序损失)
使用 NLI 数据和 SoftmaxLoss 能够产生(相对)好的句子嵌入,这多少有些巧合。MultipleNegativesRankingLoss 则更为直观,并且能产生明显更好的句子表示。
MultipleNegativesRankingLoss 的训练数据由句子对 [(a1, b1), …, (an, bn)] 组成,我们假设 (ai, bi) 是相似的句子,而当 i != j 时,(ai, bj) 是不相似的句子。该损失函数最小化 (ai, bi) 之间的距离,同时最大化所有 i != j 的情况下 (ai, bj) 之间的距离。例如,在下图中
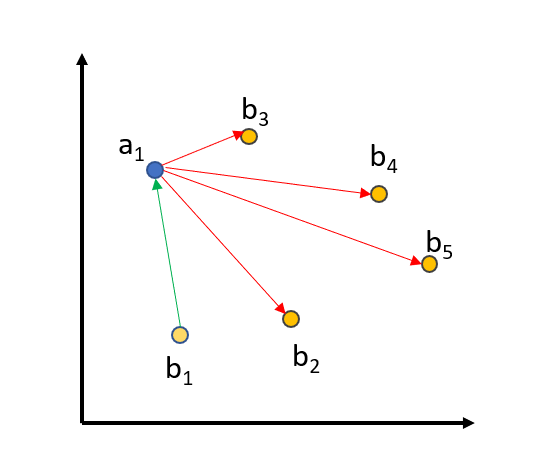
(a1, b1) 之间的距离会减小,而 (a1, b2…5) 之间的距离会增大。对 a2, …, a5 也会做同样的操作。
将 MultipleNegativesRankingLoss 与 NLI 结合使用相当简单:我们将具有 *蕴含* 标签的句子定义为正样本对。例如,我们有像 (“一场有多个男性参与的足球比赛。”, “一些男人在进行一项运动。”) 这样的句子对,并希望这些句子对在向量空间中是相近的。AllNLI 的句子对子集已经按此格式准备好。
带难负样本的 MultipleNegativesRankingLoss
我们可以通过提供三元组而非句子对来进一步改进 MultipleNegativesRankingLoss:[(a1, b1, c1), …, (an, bn, cn)]。ci 的样本是所谓的难负样本:在词汇层面上,它们与 ai 和 bi 相似,但在语义层面上,它们表达了不同的意思,因此不应该在向量空间中与 ai 相近。
对于 NLI 数据,我们可以使用矛盾标签来创建带有难负样本的三元组。因此我们的三元组看起来像这样:(”一场有多个男性参与的足球比赛。”, “一些男人在进行一项运动。”, “一群男人在打棒球比赛。”)。我们希望句子 “一场有多个男性参与的足球比赛。” 和 “一些男人在进行一项运动。” 在向量空间中是相近的,而 “一场有多个男性参与的足球比赛。” 和 “一群男人在打棒球比赛。” 之间应该有较大的距离。AllNLI 的三元组子集已经按此格式准备好。
GISTEmbedLoss
我们可以进一步扩展 MultipleNegativesRankingLoss,因为此示例中展示的批内负采样存在一些缺陷。特别是,我们自动假设 (a1, b2), …, (a1, bn) 是负样本对,但这并不总是正确的。
为了解决这个问题,GISTEmbedLoss 使用一个 Sentence Transformer 模型来指导批内负样本的选择。具体来说,如果指导模型认为 (a1, bn) 的相似度大于 (a1, b1),那么 (a1, bn) 对被认为是假负例,并因此在训练过程中被忽略。从本质上讲,这为模型带来了更高质量的训练数据。