MS MARCO
MS MARCO Passage Ranking 是一个用于训练信息检索模型的大型数据集。它包含约 50 万条来自 Bing 搜索引擎的真实搜索查询,以及能够回答这些查询的相关文本段落。
本页面展示了如何在此数据集上 训练 Sentence Transformer 模型,以便在给定查询(关键词、短语或问题)时,用于搜索文本段落。
如果您对如何使用这些模型感兴趣,请参阅 应用 - 检索与重排。
我们提供了 预训练模型,您可以直接使用,无需自己训练模型。更多信息,请参阅:预训练模型 > MSMARCO 段落模型。
双编码器
为了从大型集合中检索合适的文档,我们必须使用 Sentence Transformer(又称双编码器)模型。文档被独立地编码成固定大小的嵌入。查询也被嵌入到同一个向量空间中。然后可以使用余弦相似度或点积来找到相关文档。
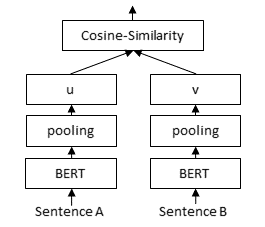
本页面介绍了在 MS MARCO 数据集上 训练双编码器 的两种策略。
MultipleNegativesRankingLoss (多负例排序损失)
当我们使用 MultipleNegativesRankingLoss 时,我们提供三元组:(query, positive_passage, negative_passage),其中 positive_passage 是与查询相关的段落,而 negative_passage 是与查询不相关的段落。我们计算语料库中所有查询、正例段落和负例段落的嵌入,然后优化以下目标:(query, positive_passage) 对在向量空间中必须接近,而 (query, negative_passage) 在向量空间中应相距较远。
为了进一步改进训练,我们使用 批内负例 (in-batch negatives)
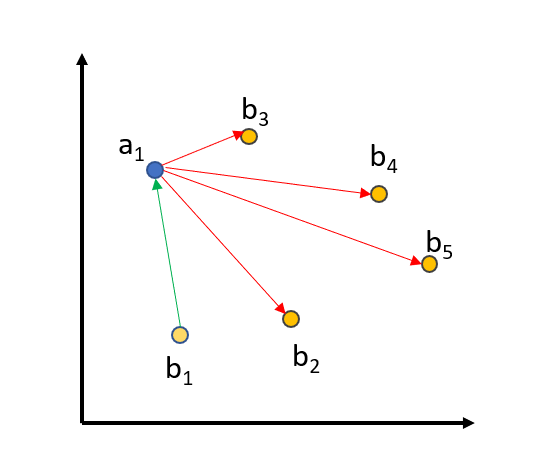
我们将所有 queries、positive_passages 和 negative_passages 嵌入到向量空间中。匹配的 (query_i, positive_passage_i) 应该接近,而一个 query 与批次中所有其他三元组的所有其他(正例/负例)段落之间应有较大距离。对于大小为 64 的批次,我们将一个查询与 64+64=128 个段落进行比较,其中只有一个段落应该接近,而其他 127 个段落应在向量空间中相距较远。
一种 改进训练 的方法是选择非常好的负例,也称为 困难负例 (hard negative):负例应与正例段落看起来非常相似,但与查询不相关。
我们通过以下方式找到这些困难负例:我们使用现有的检索系统(例如,词法搜索和其他双编码器检索系统),为每个查询找到最相关的段落。然后,我们使用一个强大的 cross-encoder/ms-marco-MiniLM-L6-v2 交叉编码器 对找到的 (query, passage) 对进行评分。我们在我们的 MS MARCO 挖掘三元组数据集集合中为 1.6 亿个此类对提供了分数。
对于 MultipleNegativesRankingLoss,我们必须确保在三元组 (query, positive_passage, negative_passage) 中,negative_passage 确实与查询不相关。不幸的是,MS MARCO 数据集 高度冗余,尽管平均只有一个段落被标记为与查询相关,但实际上它包含了许多人类会认为相关的段落。我们必须确保这些段落 不作为负例传递:我们通过在相关段落和挖掘的困难负例之间的交叉编码器分数中确保一个特定的阈值来实现这一点。默认情况下,我们设置阈值为 3:如果 (query, positive_passage) 从交叉编码器获得的分数为 9,那么我们将只考虑从交叉编码器获得分数低于 6 的负例。此阈值确保我们实际在三元组中使用的是负例。
您可以通过访问 MS MARCO 挖掘三元组数据集集合 中的任何数据集,并使用 triplet-hard 子集来找到这些数据。在所有数据集中,这涉及 1.757 亿个三元组。原始数据可以在这里找到。使用以下代码加载部分数据
from datasets import load_dataset
train_dataset = load_dataset("sentence-transformers/msmarco-co-condenser-margin-mse-sym-mnrl-mean-v1", "triplet-hard", split="train")
# Dataset({
# features: ['query', 'positive', 'negative'],
# num_rows: 11662655
# })
print(train_dataset[0])
# {'query': 'what are the liberal arts?', 'positive': 'liberal arts. 1. the academic course of instruction at a college intended to provide general knowledge and comprising the arts, humanities, natural sciences, and social sciences, as opposed to professional or technical subjects.', 'negative': "Rather than preparing students for a specific career, liberal arts programs focus on cultural literacy and hone communication and analytical skills. They often cover various disciplines, ranging from the humanities to social sciences. 1 Program Levels in Liberal Arts: Associate degree, Bachelor's degree, Master's degree."}
边距均方误差
训练代码:train_bi-encoder_margin-mse.py
MarginMSELoss 基于 Hofstätter 等人的论文。与使用 MultipleNegativesRankingLoss 进行训练时一样,我们可以使用三元组:(query, passage1, passage2)。然而,与 MultipleNegativesRankingLoss 不同,passage1 和 passage2 不必严格是正例/负例,两者对于给定的查询都可以是相关的或不相关的。
然后,我们计算 交叉编码器 对 (query, passage1) 和 (query, passage2) 的分数。我们在我们的 msmarco-hard-negatives 数据集中为 1.6 亿个此类对提供了分数。然后我们计算距离:CE_distance = CEScore(query, passage1) - CEScore(query, passage2)。
对于我们的 Sentence Transformer(例如双编码器)训练,我们将 query、passage1 和 passage2 编码成嵌入,然后测量 (query, passage1) 和 (query, passage2) 之间的点积。同样,我们测量距离:BE_distance = DotScore(query, passage1) - DotScore(query, passage2)
然后我们希望确保双编码器预测的距离与交叉编码器预测的距离接近,即,我们优化 CE_distance 和 BE_distance 之间的均方误差(MSE)。
MarginMSELoss 相对于 MultipleNegativesRankingLoss 的一个 优点 是我们 不要求 一个 positive 和一个 negative 段落。如前所述,MS MARCO 是冗余的,许多段落包含相同或相似的内容。使用 MarginMSELoss,我们可以毫无问题地对两个相关段落进行训练:在这种情况下,CE_distance 会更小,我们期望我们的双编码器也将两个段落放在向量空间中更近的位置。
MarginMSELoss 的一个 缺点 是训练时间较慢:我们需要更多的周期才能获得好的结果。在 MultipleNegativesRankingLoss 中,批次大小为 64 时,我们将一个查询与 128 个段落进行比较。而使用 MarginMSELoss,我们只将一个查询与两个段落进行比较。