损失函数
sentence_transformers.losses 定义了可用于在训练数据上微调嵌入模型的不同损失函数。损失函数的选择在微调模型时起着至关重要的作用。它决定了我们的嵌入模型在特定下游任务中的表现。
遗憾的是,没有“一刀切”的损失函数。选择哪种损失函数取决于可用的训练数据和目标任务。请查阅损失函数概览,以帮助您缩小损失函数的选择范围。
BatchAllTripletLoss
- class sentence_transformers.losses.BatchAllTripletLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function BatchHardTripletLossDistanceFunction.eucledian_distance>, margin: float = 5)[source]
BatchAllTripletLoss 接收一个包含(句子,标签)对的批次,并计算所有可能的有效三元组的损失。所谓有效三元组,即锚点(anchor)和正例(positive)必须有相同的标签,而锚点和负例(negative)的标签不同。标签必须是整数,相同的标签表示句子来自同一个类别。您的训练数据集必须每个标签类别至少包含2个样本。
- 参数:
model – SentenceTransformer 模型
distance_metric – 返回两个嵌入之间距离的函数。SiameseDistanceMetric 类包含可使用的预定义度量。
margin – 负例样本与锚点的距离应比正例至少远 margin。
参考文献
来源:https://github.com/NegatioN/OnlineMiningTripletLoss/blob/master/online_triplet_loss/losses.py
论文:In Defense of the Triplet Loss for Person Re-Identification, https://arxiv.org/abs/1703.07737
- 要求
每个句子必须用一个类别进行标记。
您的数据集每个标签类别必须至少包含2个样本。
- 输入
文本
标签
单个句子
类别
- 建议
使用
BatchSamplers.GROUP_BY_LABEL(文档)来确保每个批次每个标签类别包含2个以上的样本。
- 关系
BatchHardTripletLoss只使用最难的正例和负例样本,而不是所有可能的有效三元组。BatchHardSoftMarginTripletLoss只使用最难的正例和负例样本,而不是所有可能的有效三元组。此外,它不需要设置边距。BatchSemiHardTripletLoss只使用半难(semi-hard)三元组和有效三元组,而不是所有可能的有效三元组。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") # E.g. 0: sports, 1: economy, 2: politics train_dataset = Dataset.from_dict({ "sentence": [ "He played a great game.", "The stock is up 20%", "They won 2-1.", "The last goal was amazing.", "They all voted against the bill.", ], "label": [0, 1, 0, 0, 2], }) loss = losses.BatchAllTripletLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
BatchHardSoftMarginTripletLoss
- class sentence_transformers.losses.BatchHardSoftMarginTripletLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function BatchHardTripletLossDistanceFunction.eucledian_distance>)[source]
BatchHardSoftMarginTripletLoss 接收一个包含(句子,标签)对的批次,并计算所有可能的有效三元组的损失。所谓有效三元组,即锚点和正例必须有相同的标签,而锚点和负例的标签不同。标签必须是整数,相同的标签表示句子来自同一个类别。您的训练数据集必须每个标签类别至少包含2个样本。这种软边距(soft-margin)变体不需要设置边距。
- 参数:
model – SentenceTransformer 模型
distance_metric – 返回两个嵌入之间距离的函数。SiameseDistanceMetric 类包含可使用的预定义度量。
- 定义
- 简单三元组 (Easy triplets):
损失为0的三元组,因为
distance(anchor, positive) + margin < distance(anchor, negative)。- 困难三元组 (Hard triplets):
负例比正例更接近锚点的三元组,即
distance(anchor, negative) < distance(anchor, positive)。- 半难三元组 (Semi-hard triplets):
负例不比正例更接近锚点,但仍有正损失的三元组,即
distance(anchor, positive) < distance(anchor, negative) + margin。
参考文献
来源:https://github.com/NegatioN/OnlineMiningTripletLoss/blob/master/online_triplet_loss/losses.py
论文:In Defense of the Triplet Loss for Person Re-Identification, https://arxiv.org/abs/1703.07737
- 要求
每个句子必须用一个类别进行标记。
您的数据集每个标签类别必须至少包含2个样本。
您的数据集应包含困难正例和负例。
- 输入
文本
标签
单个句子
类别
- 建议
使用
BatchSamplers.GROUP_BY_LABEL(文档)来确保每个批次每个标签类别包含2个以上的样本。
- 关系
BatchHardTripletLoss使用用户指定的边距,而此损失则不需要设置边距。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") # E.g. 0: sports, 1: economy, 2: politics train_dataset = Dataset.from_dict({ "sentence": [ "He played a great game.", "The stock is up 20%", "They won 2-1.", "The last goal was amazing.", "They all voted against the bill.", ], "label": [0, 1, 0, 0, 2], }) loss = losses.BatchHardSoftMarginTripletLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
BatchHardTripletLoss
- class sentence_transformers.losses.BatchHardTripletLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function BatchHardTripletLossDistanceFunction.eucledian_distance>, margin: float = 5)[source]
BatchHardTripletLoss 接收一个包含(句子,标签)对的批次,并计算所有可能的有效三元组的损失。所谓有效三元组,即锚点和正例必须有相同的标签,而锚点和负例的标签不同。然后它会寻找最难的正例和最难的负例。标签必须是整数,相同的标签表示句子来自同一个类别。您的训练数据集必须每个标签类别至少包含2个样本。
- 参数:
model – SentenceTransformer 模型
distance_metric – 返回两个嵌入之间距离的函数。SiameseDistanceMetric 类包含可使用的预定义度量。
margin – 负例样本与锚点的距离应比正例至少远 margin。
- 定义
- 简单三元组 (Easy triplets):
损失为0的三元组,因为
distance(anchor, positive) + margin < distance(anchor, negative)。- 困难三元组 (Hard triplets):
负例比正例更接近锚点的三元组,即
distance(anchor, negative) < distance(anchor, positive)。- 半难三元组 (Semi-hard triplets):
负例不比正例更接近锚点,但仍有正损失的三元组,即
distance(anchor, positive) < distance(anchor, negative) + margin。
参考文献
来源:https://github.com/NegatioN/OnlineMiningTripletLoss/blob/master/online_triplet_loss/losses.py
论文:In Defense of the Triplet Loss for Person Re-Identification, https://arxiv.org/abs/1703.07737
- 要求
每个句子必须用一个类别进行标记。
您的数据集每个标签类别必须至少包含2个样本。
您的数据集应包含困难正例和负例。
- 输入
文本
标签
单个句子
类别
- 建议
使用
BatchSamplers.GROUP_BY_LABEL(文档)来确保每个批次每个标签类别包含2个以上的样本。
- 关系
BatchAllTripletLoss使用所有可能的有效三元组,而不仅仅是最难的正例和负例样本。BatchSemiHardTripletLoss只使用半难三元组和有效三元组,而不仅仅是最难的正例和负例样本。BatchHardSoftMarginTripletLoss不需要设置边距,而此损失需要。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") # E.g. 0: sports, 1: economy, 2: politics train_dataset = Dataset.from_dict({ "sentence": [ "He played a great game.", "The stock is up 20%", "They won 2-1.", "The last goal was amazing.", "They all voted against the bill.", ], "label": [0, 1, 0, 0, 2], }) loss = losses.BatchHardTripletLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
BatchSemiHardTripletLoss
- class sentence_transformers.losses.BatchSemiHardTripletLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function BatchHardTripletLossDistanceFunction.eucledian_distance>, margin: float = 5)[source]
BatchSemiHardTripletLoss 接收一个包含(标签,句子)对的批次,并计算所有可能的有效三元组的损失。所谓有效三元组,即锚点和正例必须有相同的标签,而锚点和负例的标签不同。然后它会寻找半难的正例和负例。标签必须是整数,相同的标签表示句子来自同一个类别。您的训练数据集必须每个标签类别至少包含2个样本。
- 参数:
model – SentenceTransformer 模型
distance_metric – 返回两个嵌入之间距离的函数。SiameseDistanceMetric 类包含可使用的预定义度量。
margin – 负例样本与锚点的距离应比正例至少远 margin。
- 定义
- 简单三元组 (Easy triplets):
损失为0的三元组,因为
distance(anchor, positive) + margin < distance(anchor, negative)。- 困难三元组 (Hard triplets):
负例比正例更接近锚点的三元组,即
distance(anchor, negative) < distance(anchor, positive)。- 半难三元组 (Semi-hard triplets):
负例不比正例更接近锚点,但仍有正损失的三元组,即
distance(anchor, positive) < distance(anchor, negative) + margin。
参考文献
来源:https://github.com/NegatioN/OnlineMiningTripletLoss/blob/master/online_triplet_loss/losses.py
论文:In Defense of the Triplet Loss for Person Re-Identification, https://arxiv.org/abs/1703.07737
- 要求
每个句子必须用一个类别进行标记。
您的数据集每个标签类别必须至少包含2个样本。
您的数据集应包含半难正例和负例。
- 输入
文本
标签
单个句子
类别
- 建议
使用
BatchSamplers.GROUP_BY_LABEL(文档)来确保每个批次每个标签类别包含2个以上的样本。
- 关系
BatchHardTripletLoss只使用最难的正例和负例样本,而不是仅使用半难的正例和负例。BatchAllTripletLoss使用所有可能的有效三元组,而不是仅使用半难的正例和负例。BatchHardSoftMarginTripletLoss只使用最难的正例和负例样本,而不是仅使用半难的正例和负例。此外,它不需要设置边距。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") # E.g. 0: sports, 1: economy, 2: politics train_dataset = Dataset.from_dict({ "sentence": [ "He played a great game.", "The stock is up 20%", "They won 2-1.", "The last goal was amazing.", "They all voted against the bill.", ], "label": [0, 1, 0, 0, 2], }) loss = losses.BatchSemiHardTripletLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
ContrastiveLoss (对比损失)
- class sentence_transformers.losses.ContrastiveLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function SiameseDistanceMetric.<lambda>>, margin: float = 0.5, size_average: bool = True)[source]
对比损失。期望输入是两个文本和一个值为 0 或 1 的标签。如果标签 == 1,则减小两个嵌入之间的距离。如果标签 == 0,则增大两个嵌入之间的距离。
- 参数:
model – SentenceTransformer 模型
distance_metric – 返回两个嵌入之间距离的函数。SiameseDistanceMetric 类包含可使用的预定义度量。
margin – 负例样本(标签 == 0)的距离应至少为 margin 值。
size_average – 按小批次的大小取平均值。
参考文献
- 要求
(锚点, 正例/负例) 对
- 输入
文本
标签
(锚点, 正例/负例) 对
正例为 1,负例为 0
- 关系
OnlineContrastiveLoss与此类似,但使用困难正例和困难负例对。它通常能产生更好的结果。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "sentence1": ["It's nice weather outside today.", "He drove to work."], "sentence2": ["It's so sunny.", "She walked to the store."], "label": [1, 0], }) loss = losses.ContrastiveLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
OnlineContrastiveLoss
- class sentence_transformers.losses.OnlineContrastiveLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function SiameseDistanceMetric.<lambda>>, margin: float = 0.5)[source]
这个在线对比损失 (Online Contrastive loss) 类似于
ConstrativeLoss,但它选择困难正例(距离较远的正例)和困难负例(距离较近的负例)对,并仅对这些对计算损失。此损失通常比 ContrastiveLoss 产生更好的性能。- 参数:
model – SentenceTransformer 模型
distance_metric – 返回两个嵌入之间距离的函数。SiameseDistanceMetric 类包含可使用的预定义度量。
margin – 负例样本(标签 == 0)的距离应至少为 margin 值。
参考文献
- 要求
(锚点, 正例/负例) 对
数据应包括困难正例和困难负例
- 输入
文本
标签
(锚点, 正例/负例) 对
正例为 1,负例为 0
- 关系
ContrastiveLoss与此类似,但不使用困难正例和困难负例对。OnlineContrastiveLoss通常能产生更好的结果。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "sentence1": ["It's nice weather outside today.", "He drove to work."], "sentence2": ["It's so sunny.", "She walked to the store."], "label": [1, 0], }) loss = losses.OnlineContrastiveLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
ContrastiveTensionLoss
- class sentence_transformers.losses.ContrastiveTensionLoss(model: SentenceTransformer)[source]
此损失函数仅需要单个句子,无需任何标签。正例对和负例对通过随机采样自动创建,正例对由两个相同的句子组成,负例对由两个不同的句子组成。它会创建一个编码器模型的独立副本,用于编码每对中的第一个句子。原始编码器模型则编码第二个句子。使用生成的标签(正例为1,负例为0)和二元交叉熵目标函数来比较和评分嵌入。
请注意,您必须为此损失使用 ContrastiveTensionDataLoader。ContrastiveTensionDataLoader 的 pos_neg_ratio 可用于确定每个正例对的负例对数量。
通常,推荐使用
ContrastiveTensionLossInBatchNegatives而不是此损失,因为它能提供更强的训练信号。- 参数:
model – SentenceTransformer 模型
参考文献
Semantic Re-Tuning with Contrastive Tension: https://openreview.net/pdf?id=Ov_sMNau-PF
- 输入
文本
标签
单个句子
无
- 关系
ContrastiveTensionLossInBatchNegatives使用批内负采样,这比此损失提供了更强的训练信号。
示例
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.losses import ContrastiveTensionDataLoader model = SentenceTransformer('all-MiniLM-L6-v2') train_examples = [ 'This is the 1st sentence', 'This is the 2nd sentence', 'This is the 3rd sentence', 'This is the 4th sentence', 'This is the 5th sentence', 'This is the 6th sentence', 'This is the 7th sentence', 'This is the 8th sentence', 'This is the 9th sentence', 'This is the final sentence', ] train_dataloader = ContrastiveTensionDataLoader(train_examples, batch_size=3, pos_neg_ratio=3) train_loss = losses.ContrastiveTensionLoss(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
初始化内部 Module 状态,由 nn.Module 和 ScriptModule 共享。
ContrastiveTensionLossInBatchNegatives
- class sentence_transformers.losses.ContrastiveTensionLossInBatchNegatives(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0, similarity_fct=<function cos_sim>)[source]
此损失函数仅需要单个句子,无需任何标签。正例对和负例对通过随机采样自动创建,正例对由两个相同的句子组成,负例对由两个不同的句子组成。它会创建一个编码器模型的独立副本,用于编码每对中的第一个句子。原始编码器模型则编码第二个句子。与
ContrastiveTensionLoss不同,此损失使用批内负采样策略,即负例对从批次内采样。使用批内负采样比原始的ContrastiveTensionLoss提供更强的训练信号。性能通常随着批次大小的增加而提高。请注意,您不应为此损失使用 ContrastiveTensionDataLoader,而应使用包含 InputExample 实例的普通 DataLoader。每个 InputExample 实例的两个文本应完全相同。
- 参数:
model – SentenceTransformer 模型
scale – 相似度函数的输出乘以 scale 值
similarity_fct – 句子嵌入之间的相似度函数。默认为 cos_sim。也可以设置为点积(然后将 scale 设置为 1)
参考文献
Semantic Re-Tuning with Contrastive Tension: https://openreview.net/pdf?id=Ov_sMNau-PF
- 关系
ContrastiveTensionLoss不在批次内选择负例对,因此其训练信号比此损失弱。
- 输入
文本
标签
(锚点, 锚点) 对
无
示例
from sentence_transformers import SentenceTransformer, losses from torch.utils.data import DataLoader model = SentenceTransformer('all-MiniLM-L6-v2') train_examples = [ InputExample(texts=['This is a positive pair', 'Where the distance will be minimized'], label=1), InputExample(texts=['This is a negative pair', 'Their distance will be increased'], label=0), ] train_examples = [ InputExample(texts=['This is the 1st sentence', 'This is the 1st sentence']), InputExample(texts=['This is the 2nd sentence', 'This is the 2nd sentence']), InputExample(texts=['This is the 3rd sentence', 'This is the 3rd sentence']), InputExample(texts=['This is the 4th sentence', 'This is the 4th sentence']), InputExample(texts=['This is the 5th sentence', 'This is the 5th sentence']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32) train_loss = losses.ContrastiveTensionLossInBatchNegatives(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
CoSENTLoss
- class sentence_transformers.losses.CoSENTLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0, similarity_fct=<function pairwise_cos_sim>)[source]
此类实现了 CoSENT(Cosine Sentence,余弦句子)损失。它期望每个 InputExample 由一对文本和一个浮点值标签组成,该标签表示这对文本之间的预期相似度分数。
它计算以下损失函数:
loss = logsum(1+exp(s(i,j)-s(k,l))+exp...),其中(i,j)和(k,l)是批次中任意的输入对,且(i,j)的预期相似度大于(k,l)。求和是对批次中所有满足此条件的输入对进行。一些轶事实验表明,此损失函数比
CosineSimilarityLoss产生更强的训练信号,从而实现更快的收敛和性能更优的最终模型。因此,CoSENTLoss 可以在任何训练脚本中作为CosineSimilarityLoss的直接替代品。- 参数:
model – SentenceTransformer 模型
similarity_fct – 用于计算嵌入之间成对相似度的函数。默认为
util.pairwise_cos_sim。scale – 相似度函数的输出乘以 scale 值。代表逆温度。
参考文献
更多详情,请参阅:https://kexue.fm/archives/8847
- 要求
具有相应相似度分数的句子对,分数范围在相似度函数的值域内。默认为 [-1, 1]。
- 输入
文本
标签
(句子_A, 句子_B) 对
浮点相似度分数
- 关系
AnglELoss是使用pairwise_angle_sim而非pairwise_cos_sim作为度量标准的 CoSENTLoss。CosineSimilarityLoss似乎比 CoSENTLoss 产生更弱的训练信号。在我们的实验中,推荐使用 CoSENTLoss。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "sentence1": ["It's nice weather outside today.", "He drove to work."], "sentence2": ["It's so sunny.", "She walked to the store."], "score": [1.0, 0.3], }) loss = losses.CoSENTLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
AnglELoss
- class sentence_transformers.losses.AnglELoss(model: SentenceTransformer, scale: float = 20.0)[source]
此类实现了 AnglE (Angle Optimized,角度优化) 损失。这是
CoSENTLoss的一个修改版,旨在解决以下问题:当余弦函数的波形接近其顶部或底部时,其梯度会趋近于 0。这可能会阻碍优化过程,因此 AnglE 提出在复数空间中优化角度差,以减轻这种影响。它期望每个 InputExample 由一对文本和一个浮点值标签组成,该标签表示这对文本之间的预期相似度分数。
它计算以下损失函数:
loss = logsum(1+exp(s(k,l)-s(i,j))+exp...),其中(i,j)和(k,l)是批次中任意的输入对,且(i,j)的预期相似度大于(k,l)。求和是对批次中所有满足此条件的输入对进行。这与 CoSENTLoss 相同,只是使用了不同的相似度函数。- 参数:
model – SentenceTransformer 模型
scale – 相似度函数的输出乘以 scale 值。代表逆温度。
参考文献
更多详情,请参阅:https://arxiv.org/abs/2309.12871v1
- 要求
具有相应相似度分数的句子对,分数范围在相似度函数的值域内。默认为 [-1, 1]。
- 输入
文本
标签
(句子_A, 句子_B) 对
浮点相似度分数
- 关系
CoSENTLoss是使用pairwise_cos_sim而非pairwise_angle_sim作为度量标准的 AnglELoss。CosineSimilarityLoss似乎比CoSENTLoss或AnglELoss产生更弱的训练信号。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "sentence1": ["It's nice weather outside today.", "He drove to work."], "sentence2": ["It's so sunny.", "She walked to the store."], "score": [1.0, 0.3], }) loss = losses.AnglELoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
CosineSimilarityLoss (余弦相似度损失)
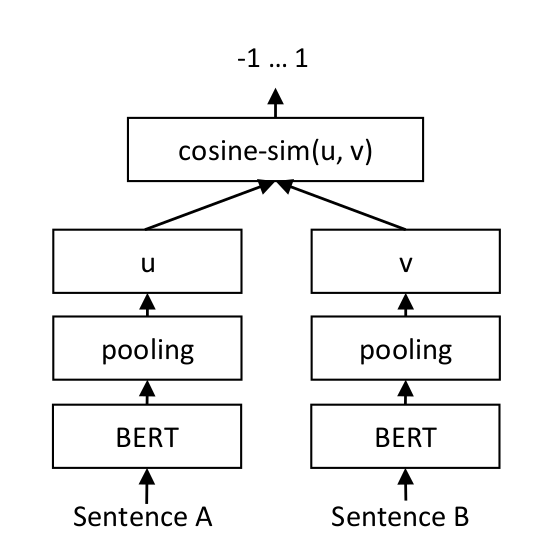
对于每个句子对,我们将句子 A 和句子 B 通过我们的网络,得到嵌入 u 和 v。使用余弦相似度计算这些嵌入的相似度,并将结果与真实的相似度分数进行比较。
这使得我们的网络能够通过微调来识别句子的相似性。
- class sentence_transformers.losses.CosineSimilarityLoss(model: SentenceTransformer, loss_fct: Module = MSELoss(), cos_score_transformation: Module = Identity())[source]
CosineSimilarityLoss 期望 InputExamples 由两个文本和一个浮点数标签组成。它计算向量
u = model(sentence_A)和v = model(sentence_B),并测量两者之间的余弦相似度。默认情况下,它最小化以下损失:||input_label - cos_score_transformation(cosine_sim(u,v))||_2。- 参数:
model – SentenceTransformer 模型
loss_fct – 应该使用哪个 PyTorch 损失函数来比较
cosine_similarity(u, v)和 input_label?默认情况下,使用 MSE:||input_label - cosine_sim(u, v)||_2cos_score_transformation – cos_score_transformation 函数应用于 cosine_similarity 的结果之上。默认情况下,使用恒等函数(即不做任何改变)。
参考文献
- 要求
具有相应相似度分数的句子对,分数范围在 [0, 1]
- 输入
文本
标签
(句子_A, 句子_B) 对
浮点相似度分数
- 关系
CoSENTLoss似乎比 CosineSimilarityLoss 产生更强的训练信号。在我们的实验中,推荐使用 CoSENTLoss。AnglELoss是使用pairwise_angle_sim作为度量标准的CoSENTLoss,而非pairwise_cos_sim。它也比 CosineSimilarityLoss 产生更强的训练信号。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "sentence1": ["It's nice weather outside today.", "He drove to work."], "sentence2": ["It's so sunny.", "She walked to the store."], "score": [1.0, 0.3], }) loss = losses.CosineSimilarityLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
DenoisingAutoEncoderLoss
- class sentence_transformers.losses.DenoisingAutoEncoderLoss(model: SentenceTransformer, decoder_name_or_path: str | None = None, tie_encoder_decoder: bool = True)[source]
该损失函数期望输入的是一对损坏的句子和对应的原始句子。在训练过程中,解码器从编码后的句子嵌入中重建原始句子。这里的参数 ‘decoder_name_or_path’ 指示了用作解码器的预训练模型(由 Hugging Face 支持)。由于包含了解码过程,此处的解码器应有一个名为 XXXLMHead 的类(在 Hugging Face 的 Transformers 上下文中)。‘tie_encoder_decoder’ 标志指示是否绑定编码器和解码器的可训练参数,这被证明对模型性能有益,同时限制了所需内存量。只有当编码器和解码器来自相同架构时,‘tie_encoder_decoder’ 标志才能生效。
数据生成过程(即“损坏”过程)已在
DenoisingAutoEncoderDataset中实现,允许您只提供常规句子。- 参数:
model (SentenceTransformer) – SentenceTransformer 模型。
decoder_name_or_path (str, 可选) – 用于初始化解码器的模型名称或路径(与 Hugging Face 的 Transformers 兼容)。默认为 None。
tie_encoder_decoder (bool) – 是否绑定编码器和解码器的可训练参数。默认为 True。
参考文献
- 要求
解码器应有一个名为 XXXLMHead 的类(在 Hugging Face 的 Transformers 上下文中)
应使用大型语料库
- 输入
文本
标签
(损坏的句子, 原始句子) 对
无
通过
DenoisingAutoEncoderDataset提供的句子无
示例
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.datasets import DenoisingAutoEncoderDataset from torch.utils.data import DataLoader model_name = "bert-base-cased" model = SentenceTransformer(model_name) train_sentences = [ "First training sentence", "Second training sentence", "Third training sentence", "Fourth training sentence", ] batch_size = 2 train_dataset = DenoisingAutoEncoderDataset(train_sentences) train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True) train_loss = losses.DenoisingAutoEncoderLoss( model, decoder_name_or_path=model_name, tie_encoder_decoder=True ) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=10, )
GISTEmbedLoss
- class sentence_transformers.losses.GISTEmbedLoss(model: SentenceTransformer, guide: SentenceTransformer, temperature: float = 0.01, margin_strategy: Literal['absolute', 'relative'] = 'absolute', margin: float = 0.0, contrast_anchors: bool = True, contrast_positives: bool = True, gather_across_devices: bool = False)[source]
该损失函数用于通过 GISTEmbed 算法训练 SentenceTransformer 模型。它接收一个模型和一个指导模型作为输入,并使用指导模型来指导批内负样本的选择。余弦相似度用于计算损失,温度参数用于缩放余弦相似度。
您可以应用不同的假阴性过滤策略来丢弃与正样本过于相似的困难负样本。支持两种策略:
“absolute”:丢弃相似度分数大于或等于
positive_score - margin的负样本。“relative”:丢弃相似度分数大于或等于
positive_score * (1 - margin)的负样本。
- 参数:
model – 基于 transformers 模型的 SentenceTransformer 模型。
guide – 用于指导批内负样本选择的 SentenceTransformer 模型。
temperature – 用于缩放余弦相似度的温度参数。是
MultipleNegativesRankingLoss中scale参数的倒数。margin_strategy – 用于假阴性过滤的策略。可选值为 {“absolute”, “relative”}。
margin – 用于过滤负样本的边距值。默认为 0.0,与“absolute”策略一起使用时,这只会移除那些与查询的相似度高于正样本与查询相似度的负样本。
contrast_anchors – 如果为 True,则在损失计算中包含锚点-锚点对,从而使锚点的嵌入被推得更远。默认为 True,遵循原始 GISTEmbed 论文。
contrast_positives – 如果为 True,则在损失计算中包含正样本-正样本对,从而使正样本的嵌入被推得更远。默认为 True,遵循原始 GISTEmbed 论文,但在某些检索任务中设置为 False 可能会产生更好的结果。
gather_across_devices – 如果为 True,则在计算损失之前跨所有设备收集嵌入。在多 GPU 上训练时推荐使用,因为它允许更大的批处理大小,但可能会因通信开销而减慢训练速度,并可能导致内存不足错误。
参考文献
更多详情,请参阅:https://arxiv.org/abs/2402.16829
- 要求
(锚点, 正例, 负例) 三元组
(锚点, 正例) 对
- 输入
文本
标签
(锚点, 正例, 负例) 三元组
无
(锚点, 正例) 对
无
- 建议
使用
BatchSamplers.NO_DUPLICATES(文档) 以确保批内负样本不是锚点或正样本的副本。
- 关系
MultipleNegativesRankingLoss与此损失函数类似,但它不使用指导模型来指导批内负样本的选择。GISTEmbedLoss 以一些训练开销为代价,产生了更强的训练信号。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") guide = SentenceTransformer("all-MiniLM-L6-v2") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.GISTEmbedLoss(model, guide) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
CachedGISTEmbedLoss
- class sentence_transformers.losses.CachedGISTEmbedLoss(model: SentenceTransformer, guide: SentenceTransformer, temperature: float = 0.01, mini_batch_size: int = 32, show_progress_bar: bool = False, margin_strategy: Literal['absolute', 'relative'] = 'absolute', margin: float = 0.0, contrast_anchors: bool = True, contrast_positives: bool = True, gather_across_devices: bool = False)[source]
该损失函数是
GISTEmbedLoss和CachedMultipleNegativesRankingLoss的结合。通常,MultipleNegativesRankingLoss需要更大的批处理大小才能获得更好的性能。GISTEmbedLoss由于使用指导模型进行批内负样本选择,因此比MultipleNegativesRankingLoss产生更强的训练信号。同时,CachedMultipleNegativesRankingLoss通过将计算分为嵌入和损失计算两个阶段,允许扩展批处理大小,这两个阶段都可以通过小批量进行扩展 (https://arxiv.org/pdf/2101.06983.pdf)。通过结合
GISTEmbedLoss的指导选择和CachedMultipleNegativesRankingLoss的梯度缓存,可以在保持与GISTEmbedLoss相当的性能水平的同时,减少内存使用。您可以应用不同的假阴性过滤策略来丢弃与正样本过于相似的困难负样本。支持两种策略:
“absolute”:丢弃相似度分数大于或等于
positive_score - margin的负样本。“relative”:丢弃相似度分数大于或等于
positive_score * (1 - margin)的负样本。
- 参数:
model – SentenceTransformer 模型
guide – 用于指导批内负样本选择的 SentenceTransformer 模型。
temperature – 用于缩放余弦相似度的温度参数。
mini_batch_size – 前向传递的小批量大小,这表示训练和评估期间实际使用的内存量。小批量大小越大,训练的内存效率越高,但训练速度会越慢。建议将其设置为您的 GPU 内存允许的最高值。默认值为 32。
show_progress_bar – 如果为 True,则在训练期间显示小批量的进度条。默认为 False。
margin_strategy – 用于假阴性过滤的策略。可选值为 {“absolute”, “relative”}。
margin – 用于过滤负样本的边距值。默认为 0.0,与“absolute”策略一起使用时,这只会移除那些与查询的相似度高于正样本与查询相似度的负样本。
contrast_anchors – 如果为 True,则在损失计算中包含锚点-锚点对,从而使锚点的嵌入被推得更远。默认为 True,遵循原始 GISTEmbed 论文。
contrast_positives – 如果为 True,则在损失计算中包含正样本-正样本对,从而使正样本的嵌入被推得更远。默认为 True,遵循原始 GISTEmbed 论文,但在某些检索任务中设置为 False 可能会产生更好的结果。
gather_across_devices – 如果为 True,则在计算损失之前跨所有设备收集嵌入。在多 GPU 上训练时推荐使用,因为它允许更大的批处理大小,但可能会因通信开销而减慢训练速度,并可能导致内存不足错误。
参考文献
Efficient Natural Language Response Suggestion for Smart Reply, 第 4.4 节:https://arxiv.org/pdf/1705.00652.pdf
在内存受限设置下扩展深度对比学习批处理大小:https://arxiv.org/pdf/2101.06983.pdf
GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning https://arxiv.org/abs/2402.16829
- 要求
(锚点, 正样本) 对或 (锚点, 正样本, 负样本) 对
应与大批量大小一起使用以获得卓越性能,但训练时间比
MultipleNegativesRankingLoss慢
- 输入
文本
标签
(锚点, 正例) 对
无
(锚点, 正例, 负例) 三元组
无
(anchor, positive, negative_1, ..., negative_n)
无
- 建议
使用
BatchSamplers.NO_DUPLICATES(文档) 以确保批内负样本不是锚点或正样本的副本。
- 关系
等同于
GISTEmbedLoss,但带有缓存功能,允许更高的批处理大小
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") guide = SentenceTransformer("all-MiniLM-L6-v2") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.CachedGISTEmbedLoss( model, guide, mini_batch_size=64, margin_strategy="absolute", # or "relative" (e.g., margin=0.05 for max. 95% of positive similarity) margin=0.1 ) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
MSELoss
- class sentence_transformers.losses.MSELoss(model: SentenceTransformer)[source]
计算计算出的句子嵌入与目标句子嵌入之间的均方误差(MSE)损失。该损失用于将句子嵌入扩展到新语言,如我们的出版物《使用知识蒸馏使单语句子嵌入多语化》中所述。
有关示例,请参阅关于将语言模型扩展到新语言的蒸馏文档。
- 参数:
model – SentenceTransformer 模型
参考文献
使用知识蒸馏使单语句子嵌入多语化:https://arxiv.org/abs/2004.09813
- 要求
通常在知识蒸馏设置中使用经过微调的教师模型 M
- 输入
文本
标签
句子
模型句子嵌入
句子_1, 句子_2, …, 句子_N
模型句子嵌入
- 关系
MarginMSELoss与此损失等效,但通过一个负样本对引入了边距。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset student_model = SentenceTransformer("microsoft/mpnet-base") teacher_model = SentenceTransformer("all-mpnet-base-v2") train_dataset = Dataset.from_dict({ "english": ["The first sentence", "The second sentence", "The third sentence", "The fourth sentence"], "french": ["La première phrase", "La deuxième phrase", "La troisième phrase", "La quatrième phrase"], }) def compute_labels(batch): return { "label": teacher_model.encode(batch["english"]) } train_dataset = train_dataset.map(compute_labels, batched=True) loss = losses.MSELoss(student_model) trainer = SentenceTransformerTrainer( model=student_model, train_dataset=train_dataset, loss=loss, ) trainer.train()
MarginMSELoss
- class sentence_transformers.losses.MarginMSELoss(model: SentenceTransformer, similarity_fct=<function pairwise_dot_score>)[source]
计算
|sim(Query, Pos) - sim(Query, Neg)|和|gold_sim(Query, Pos) - gold_sim(Query, Neg)|之间的均方误差损失。默认情况下,sim() 是点积。gold_sim 通常是来自教师模型的相似度分数。与
MultipleNegativesRankingLoss相比,这两个段落不必严格是正样本和负样本,对于给定的查询,两者都可以是相关的或不相关的。这可能是 MarginMSELoss 相对于 MultipleNegativesRankingLoss 的一个优势,但请注意,MarginMSELoss 的训练速度要慢得多。使用 MultipleNegativesRankingLoss,批处理大小为 64 时,我们将一个查询与 128 个段落进行比较。而使用 MarginMSELoss,我们只将一个查询与两个段落进行比较。也可以将多个负样本与 MarginMSELoss 一起使用,但训练会更慢。- 参数:
model – SentenceTransformer 模型
similarity_fct – 使用哪种相似度函数。
参考文献
- 要求
(查询, 段落一, 段落二) 三元组 或 (查询, 正样本, 负样本_1, …, 负样本_n)
通常在知识蒸馏设置中使用经过微调的教师模型 M
- 输入
文本
标签
(查询, 段落_一, 段落_二) 三元组
M(查询, 段落一) - M(查询, 段落二)
(查询, 段落_一, 段落_二) 三元组
[M(查询, 段落一), M(查询, 段落二)]
(查询, 正例, 负例_1, ..., 负例_n)
[M(查询, 正样本) - M(查询, 负样本_i) for i in 1..n]
(查询, 正例, 负例_1, ..., 负例_n)
[M(查询, 正样本), M(查询, 负样本_1), …, M(查询, 负样本_n)]
- 关系
MSELoss与此损失类似,但没有通过负样本对引入边距。
示例
使用黄金标签,例如,如果你有句子的硬分数。假设你希望模型将具有相似“质量”的句子嵌入到相近的位置。如果“text1”的质量是 5 分(满分 5 分),“text2”的质量是 1 分(满分 5 分),“text3”的质量是 3 分(满分 5 分),那么一对的相似度可以定义为质量分数的差异。所以,“text1”和“text2”之间的相似度是 4,“text1”和“text3”之间的相似度是 2。如果我们用这个作为我们的“教师模型”,标签就变成了 similarity(“text1”, “text2”) - similarity(“text1”, “text3”) = 4 - 2 = 2。
正值表示第一个段落比第二个段落与查询更相似,而负值表示相反。
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "text1": ["It's nice weather outside today.", "He drove to work."], "text2": ["It's so sunny.", "He took the car to work."], "text3": ["It's very sunny.", "She walked to the store."], "label": [0.1, 0.8], }) loss = losses.MarginMSELoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
我们也可以使用教师模型来计算相似度分数。在这种情况下,我们可以使用教师模型计算相似度分数,并将其用作白银标签。这通常用于知识蒸馏。
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset student_model = SentenceTransformer("microsoft/mpnet-base") teacher_model = SentenceTransformer("all-mpnet-base-v2") train_dataset = Dataset.from_dict({ "query": ["It's nice weather outside today.", "He drove to work."], "passage1": ["It's so sunny.", "He took the car to work."], "passage2": ["It's very sunny.", "She walked to the store."], }) def compute_labels(batch): emb_queries = teacher_model.encode(batch["query"]) emb_passages1 = teacher_model.encode(batch["passage1"]) emb_passages2 = teacher_model.encode(batch["passage2"]) return { "label": teacher_model.similarity_pairwise(emb_queries, emb_passages1) - teacher_model.similarity_pairwise(emb_queries, emb_passages2) } train_dataset = train_dataset.map(compute_labels, batched=True) loss = losses.MarginMSELoss(student_model) trainer = SentenceTransformerTrainer( model=student_model, train_dataset=train_dataset, loss=loss, ) trainer.train()
我们还可以在知识蒸馏过程中使用多个负样本。
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset import torch student_model = SentenceTransformer("microsoft/mpnet-base") teacher_model = SentenceTransformer("all-mpnet-base-v2") train_dataset = Dataset.from_dict( { "query": ["It's nice weather outside today.", "He drove to work."], "passage1": ["It's so sunny.", "He took the car to work."], "passage2": ["It's very cold.", "She walked to the store."], "passage3": ["Its rainy", "She took the bus"], } ) def compute_labels(batch): emb_queries = teacher_model.encode(batch["query"]) emb_passages1 = teacher_model.encode(batch["passage1"]) emb_passages2 = teacher_model.encode(batch["passage2"]) emb_passages3 = teacher_model.encode(batch["passage3"]) return { "label": torch.stack( [ teacher_model.similarity_pairwise(emb_queries, emb_passages1) - teacher_model.similarity_pairwise(emb_queries, emb_passages2), teacher_model.similarity_pairwise(emb_queries, emb_passages1) - teacher_model.similarity_pairwise(emb_queries, emb_passages3), ], dim=1, ) } train_dataset = train_dataset.map(compute_labels, batched=True) loss = losses.MarginMSELoss(student_model) trainer = SentenceTransformerTrainer(model=student_model, train_dataset=train_dataset, loss=loss) trainer.train()
MatryoshkaLoss
- class sentence_transformers.losses.MatryoshkaLoss(model: SentenceTransformer, loss: nn.Module, matryoshka_dims: list[int], matryoshka_weights: list[float | int] | None = None, n_dims_per_step: int = -1)[source]
MatryoshkaLoss 可以看作是一个损失*修饰符*,它允许您在各种不同的嵌入维度上使用其他损失函数。这在您希望训练一个模型,而用户可以选择降低嵌入维度以提高嵌入比较速度和降低成本时非常有用。
此损失还与 Cached… 损失兼容,这些是允许更高批处理大小的批内负样本损失。更高的批处理大小允许更多的负样本,并通常能产生更强的模型。
- 参数:
model – SentenceTransformer 模型
loss – 要使用的损失函数,例如
MultipleNegativesRankingLoss,CoSENTLoss等。matryoshka_dims – 用于损失函数的嵌入维度列表,例如 [768, 512, 256, 128, 64]。
matryoshka_weights – 用于损失函数的权重列表,例如 [1, 1, 1, 1, 1]。如果为 None,则所有维度的权重将设置为 1。
n_dims_per_step – 每一步使用的维度数。如果为 -1,则使用所有维度。如果 > 0,则每一步使用 n_dims_per_step 个维度的随机样本。默认值为 -1。
参考文献
这个概念是在这篇论文中提出的:https://arxiv.org/abs/2205.13147
- 输入
文本
标签
任何
任何
- 关系
Matryoshka2dLoss结合了此损失和AdaptiveLayerLoss,这允许通过减少层数来加快推理速度。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.MultipleNegativesRankingLoss(model) loss = losses.MatryoshkaLoss(model, loss, [768, 512, 256, 128, 64]) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
Matryoshka2dLoss
- class sentence_transformers.losses.Matryoshka2dLoss(model: SentenceTransformer, loss: Module, matryoshka_dims: list[int], matryoshka_weights: list[float | int] | None = None, n_layers_per_step: int = 1, n_dims_per_step: int = 1, last_layer_weight: float = 1.0, prior_layers_weight: float = 1.0, kl_div_weight: float = 1.0, kl_temperature: float = 0.3)[源代码]
Matryoshka2dLoss 可以被看作是一个损失*修改器*,它结合了
AdaptiveLayerLoss和MatryoshkaLoss。这使您可以训练一个嵌入模型,该模型 1) 允许用户指定要使用的模型层数,以及 2) 允许用户指定要使用的输出维度。前者在您希望用户可以选择减少使用的层数以提高其推理速度和内存使用量时非常有用,而后者在您希望用户可以选择降低输出维度以提高其下游任务(例如检索)的效率或降低存储成本时非常有用。
注意,这默认使用 n_layers_per_step=1 和 n_dims_per_step=1,遵循原始的 2DMSE 实现。
- 参数:
model – SentenceTransformer 模型
loss – 要使用的损失函数,例如
MultipleNegativesRankingLoss,CoSENTLoss等。matryoshka_dims – 用于损失函数的嵌入维度列表,例如 [768, 512, 256, 128, 64]。
matryoshka_weights – 用于损失函数的权重列表,例如 [1, 1, 1, 1, 1]。如果为 None,则所有维度的权重将设置为 1。
n_layers_per_step – 每步使用的层数。如果为-1,则使用所有层。如果 > 0,则每步随机抽样 n_layers_per_step 个层。2DMSE 论文使用 n_layers_per_step=1。默认值为 -1。
n_dims_per_step – 每一步使用的维度数。如果为 -1,则使用所有维度。如果 > 0,则每一步使用 n_dims_per_step 个维度的随机样本。默认值为 -1。
last_layer_weight – 最后一层损失的权重。增加此值可更关注使用所有层时的性能。默认值为 1.0。
prior_layers_weight – 先前层损失的权重。增加此值可更关注使用较少层时的性能。默认值为 1.0。
kl_div_weight – KL 散度损失的权重,用于使先前层的表现与最后一层相匹配。增加此值可更关注使用较少层时的性能。默认值为 1.0。
kl_temperature – KL 散度损失的温度。如果为 0,则不使用 KL 散度损失。默认值为 1.0。
参考文献
参见 2D Matryoshka Sentence Embeddings (2DMSE) 论文: https://arxiv.org/abs/2402.14776
- 要求
- 输入
文本
标签
任何
任何
- 关系
此损失中使用了
MatryoshkaLoss,它负责维度缩减。此损失中使用了
AdaptiveLayerLoss,它负责层数缩减。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.MultipleNegativesRankingLoss(model) loss = losses.Matryoshka2dLoss(model, loss, [768, 512, 256, 128, 64]) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
AdaptiveLayerLoss
- class sentence_transformers.losses.AdaptiveLayerLoss(model: SentenceTransformer, loss: nn.Module, n_layers_per_step: int = 1, last_layer_weight: float = 1.0, prior_layers_weight: float = 1.0, kl_div_weight: float = 1.0, kl_temperature: float = 0.3)[源代码]
AdaptiveLayerLoss 可以被看作是一个损失*修改器*,它允许您在 Sentence Transformer 模型的非最终层上使用其他损失函数。这在您希望训练一个模型,让用户可以选择减少使用的层数以提高其推理速度和内存使用量时非常有用。
- 参数:
model – SentenceTransformer 模型
loss – 要使用的损失函数,例如
MultipleNegativesRankingLoss,CoSENTLoss等。n_layers_per_step – 每步使用的层数。如果为 -1,则使用所有层。如果 > 0,则每步随机抽样 n_layers_per_step 个层,这与总是被使用的最后一层是分开的。2DMSE 论文使用 n_layers_per_step=1。默认值为 1。
last_layer_weight – 最后一层损失的权重。增加此值可更关注使用所有层时的性能。默认值为 1.0。
prior_layers_weight – 先前层损失的权重。增加此值可更关注使用较少层时的性能。默认值为 1.0。
kl_div_weight – KL 散度损失的权重,用于使先前层的表现与最后一层相匹配。增加此值可更关注使用较少层时的性能。默认值为 1.0。
kl_temperature – KL 散度损失的温度。如果为 0,则不使用 KL 散度损失。默认值为 1.0。
参考文献
这个概念的灵感来自 2DMSE 论文: https://arxiv.org/abs/2402.14776
- 要求
- 输入
文本
标签
任何
任何
- 关系
Matryoshka2dLoss将此损失与MatryoshkaLoss结合使用,从而实现输出维度缩减,以加快下游任务(例如检索)的速度。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.MultipleNegativesRankingLoss(model=model) loss = losses.AdaptiveLayerLoss(model, loss) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
MegaBatchMarginLoss
- class sentence_transformers.losses.MegaBatchMarginLoss(model: SentenceTransformer, positive_margin: float = 0.8, negative_margin: float = 0.3, use_mini_batched_version: bool = True, mini_batch_size: int = 50)[源代码]
给定一个大批量(例如 500 个或更多样本)的 (anchor_i, positive_i) 对,为批次中的每个对找到最难的负样本,即找到 j != i,使得 cos_sim(anchor_i, positive_j) 最大化。然后,由此创建一个三元组 (anchor_i, positive_i, positive_j),其中 positive_j 作为此三元组的负样本。
然后像三元组损失一样进行训练。
- 参数:
model – SentenceTransformer 模型
positive_margin – 正边距,cos(anchor, positive) 应 > positive_margin
negative_margin – 负边距,cos(anchor, negative) 应 < negative_margin
use_mini_batched_version – 由于大批量需要大量内存,我们可以使用一个微批次版本。我们将大批量分解为更小的批次,包含更少的样本。
mini_batch_size – 微批次的大小。应该是您数据加载器中批次大小的约数。
参考文献
此损失函数的灵感来自 ParaNMT 论文: https://www.aclweb.org/anthology/P18-1042/
- 要求
(锚点, 正例) 对
大批量(500 个或更多样本)
- 输入
文本
标签
(锚点, 正例) 对
无
- 建议
使用
BatchSamplers.NO_DUPLICATES(文档) 以确保批内负样本不是锚点或正样本的副本。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainingArguments, SentenceTransformerTrainer, losses from datasets import Dataset train_batch_size = 250 train_mini_batch_size = 32 model = SentenceTransformer('all-MiniLM-L6-v2') train_dataset = Dataset.from_dict({ "anchor": [f"This is sentence number {i}" for i in range(500)], "positive": [f"This is sentence number {i}" for i in range(1, 501)], }) loss = losses.MegaBatchMarginLoss(model=model, mini_batch_size=train_mini_batch_size) args = SentenceTransformerTrainingArguments( output_dir="output", per_device_train_batch_size=train_batch_size, ) trainer = SentenceTransformerTrainer( model=model, args=args, train_dataset=train_dataset, loss=loss, ) trainer.train()
MultipleNegativesRankingLoss (多负例排序损失)
如果您只有正样本对,例如只有相似文本对(如释义对、重复问题对、(查询, 响应) 对或 (源语言, 目标语言) 对),那么 *MultipleNegativesRankingLoss* 是一个很好的损失函数。
- class sentence_transformers.losses.MultipleNegativesRankingLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0, similarity_fct=<function cos_sim>, gather_across_devices: bool = False)[源代码]
给定一个 (anchor, positive) 对或 (anchor, positive, negative) 三元组列表,此损失函数优化以下目标
给定一个锚点(例如一个问题),在批次中的每一个正例和负例(例如所有答案)中,为对应的正例(即答案)赋予最高的相似度。
如果您提供可选的负样本,它们都将被用作额外的选项,模型必须从中选择正确的正样本。在合理的范围内,这种“选择”越困难,模型就会变得越强大。因此,更高的批次大小会产生更多的批内负样本,从而(在一定程度上)提高性能。
这个损失函数非常适合训练用于检索设置的嵌入,其中您有正样本对(例如 (查询, 答案)),因为它会在每个批次中随机抽样
n-1个负样本文件。此损失函数也称为 InfoNCE 损失、SimCSE 损失、带批内负例的交叉熵损失,或简称为批内负例损失。
- 参数:
model – SentenceTransformer 模型
scale – 相似度函数的输出乘以 scale 值。在一些文献中,缩放参数被称为温度,它是 scale 的倒数。简而言之:scale = 1 / temperature,所以 scale=20.0 等价于 temperature=0.05。
similarity_fct – 句子嵌入之间的相似度函数。默认为 cos_sim。也可以设置为点积(然后将 scale 设置为 1)
gather_across_devices – 如果为 True,则在计算损失之前跨所有设备收集嵌入。在多 GPU 上训练时推荐使用,因为它允许更大的批处理大小,但可能会因通信开销而减慢训练速度,并可能导致内存不足错误。
参考文献
Efficient Natural Language Response Suggestion for Smart Reply, 第 4.4 节:https://arxiv.org/pdf/1705.00652.pdf
- 要求
(anchor, positive) 对或 (anchor, positive, negative) 三元组
- 输入
文本
标签
(锚点, 正例) 对
无
(锚点, 正例, 负例) 三元组
无
(anchor, positive, negative_1, ..., negative_n)
无
- 建议
使用
BatchSamplers.NO_DUPLICATES(文档) 以确保批内负样本不是锚点或正样本的副本。
- 关系
CachedMultipleNegativesRankingLoss与此损失等价,但它使用缓存,允许更大的批次大小(从而获得更好的性能),而无需额外的内存使用。然而,它的速度稍慢。MultipleNegativesSymmetricRankingLoss与此损失等价,但增加了一个额外的损失项。GISTEmbedLoss与此损失等价,但使用一个引导模型来指导批内负样本的选择。GISTEmbedLoss 以一些训练开销为代价,产生更强的训练信号。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.MultipleNegativesRankingLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
CachedMultipleNegativesRankingLoss
- class sentence_transformers.losses.CachedMultipleNegativesRankingLoss(model: SentenceTransformer, scale: float = 20.0, similarity_fct: callable[[Tensor, Tensor], Tensor] = <function cos_sim>, mini_batch_size: int = 32, gather_across_devices: bool = False, show_progress_bar: bool = False)[源代码]
MultipleNegativesRankingLoss (https://arxiv.org/pdf/1705.00652.pdf) 的增强版,通过 GradCache (https://arxiv.org/pdf/2101.06983.pdf) 实现。
使用批内负样本的对比学习(这里是我们的 MNRL 损失)通常由于 (GPU) 内存限制而难以处理大批量。即使使用像梯度缩放这样的批次缩放方法,也无法工作。这是因为批内负样本使得同一批次内的数据点非独立,因此批次无法分解为微批次。GradCache 是解决此问题的聪明方法。它通过将计算分为嵌入和损失计算两个阶段来实现目标,这两个阶段都可以通过微批次进行缩放。结果是,恒定大小的内存(例如,适用于批次大小 = 32 的内存)现在可以处理大得多的批次(例如,65536)。
详细信息
它首先在没有梯度/计算图的情况下快速进行嵌入步骤,以获取所有嵌入;
计算损失,反向传播至嵌入,并缓存关于嵌入的梯度;
第二次嵌入步骤,带有梯度/计算图,并将缓存的梯度连接到反向传播链中。
注意:所有步骤都通过微批次完成。在 GradCache 的原始实现中,(2) 不是以微批次完成的,当批次较大时需要大量内存。一个缺点是速度。根据论文,梯度缓存会牺牲大约 20% 的计算时间。
- 参数:
model – SentenceTransformer 模型
scale – 相似度函数的输出乘以 scale 值。在一些文献中,缩放参数被称为温度,它是 scale 的倒数。简而言之:scale = 1 / temperature,所以 scale=20.0 等价于 temperature=0.05。
similarity_fct – 句子嵌入之间的相似度函数。默认为 cos_sim。也可以设置为点积(然后将 scale 设置为 1)
mini_batch_size – 前向传递的小批量大小,这表示训练和评估期间实际使用的内存量。小批量大小越大,训练的内存效率越高,但训练速度会越慢。建议将其设置为您的 GPU 内存允许的最高值。默认值为 32。
gather_across_devices – 如果为 True,则在计算损失之前跨所有设备收集嵌入。在多 GPU 上训练时推荐使用,因为它允许更大的批处理大小,但可能会因通信开销而减慢训练速度,并可能导致内存不足错误。
show_progress_bar – 如果为 True,则在训练期间显示小批量的进度条。默认为 False。
参考文献
Efficient Natural Language Response Suggestion for Smart Reply, 第 4.4 节:https://arxiv.org/pdf/1705.00652.pdf
在内存受限设置下扩展深度对比学习批处理大小:https://arxiv.org/pdf/2101.06983.pdf
- 要求
(锚点, 正样本) 对或 (锚点, 正样本, 负样本) 对
应与大的 per_device_train_batch_size 和低的 mini_batch_size 结合使用以获得卓越性能,但训练时间比
MultipleNegativesRankingLoss慢。
- 输入
文本
标签
(锚点, 正例) 对
无
(锚点, 正例, 负例) 三元组
无
(anchor, positive, negative_1, ..., negative_n)
无
- 建议
使用
BatchSamplers.NO_DUPLICATES(文档) 以确保批内负样本不是锚点或正样本的副本。
- 关系
等价于
MultipleNegativesRankingLoss,但带有缓存机制,允许更大的批次大小(从而获得更好的性能),而无需额外的内存使用。此损失的训练速度也比MultipleNegativesRankingLoss慢约 2 到 2.4 倍。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.CachedMultipleNegativesRankingLoss(model, mini_batch_size=64) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
MultipleNegativesSymmetricRankingLoss
- class sentence_transformers.losses.MultipleNegativesSymmetricRankingLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0, similarity_fct=<function cos_sim>, gather_across_devices: bool = False)[源代码]
给定一个 (anchor, positive) 对的列表,此损失计算以下两个损失之和
前向损失:给定一个 anchor,从批次中的所有 positive 中找到相似度最高的样本。这等价于
MultipleNegativesRankingLoss。后向损失:给定一个 positive,从批次中的所有 anchor 中找到相似度最高的样本。
例如,对于问答对,
MultipleNegativesRankingLoss仅计算给定问题找到答案的损失,而MultipleNegativesSymmetricRankingLoss还额外计算给定答案找到问题的损失。注意:如果您传递三元组,负样本条目将被忽略。只为 anchor 搜索 positive。
- 参数:
model – SentenceTransformer 模型
scale – 相似度函数的输出乘以 scale 值。在一些文献中,缩放参数被称为温度,它是 scale 的倒数。简而言之:scale = 1 / temperature,所以 scale=20.0 等价于 temperature=0.05。
similarity_fct – 句子嵌入之间的相似度函数。默认为 cos_sim。也可以设置为点积(然后将 scale 设置为 1)
gather_across_devices – 如果为 True,则在计算损失之前跨所有设备收集嵌入。在多 GPU 上训练时推荐使用,因为它允许更大的批处理大小,但可能会因通信开销而减慢训练速度,并可能导致内存不足错误。
- 要求
(锚点, 正例) 对
- 输入
文本
标签
(锚点, 正例) 对
无
- 建议
使用
BatchSamplers.NO_DUPLICATES(文档) 以确保批内负样本不是锚点或正样本的副本。
- 关系
类似于
MultipleNegativesRankingLoss,但增加了一个额外的损失项。CachedMultipleNegativesSymmetricRankingLoss与此损失等价,但它使用缓存,允许更大的批次大小(从而获得更好的性能),而无需额外的内存使用。然而,它的速度稍慢。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.MultipleNegativesSymmetricRankingLoss(model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
CachedMultipleNegativesSymmetricRankingLoss
- class sentence_transformers.losses.CachedMultipleNegativesSymmetricRankingLoss(model: SentenceTransformer, scale: float = 20.0, similarity_fct: callable[[Tensor, Tensor], Tensor] = <function cos_sim>, mini_batch_size: int = 32, gather_across_devices: bool = False, show_progress_bar: bool = False)[源代码]
MultipleNegativesSymmetricRankingLoss(MNSRL) 的增强版,通过 GradCache (https://arxiv.org/pdf/2101.06983.pdf) 实现。给定一个 (anchor, positive) 对的列表,MNSRL 计算以下两个损失之和
前向损失:给定一个 anchor,从批次中的所有 positive 中找到相似度最高的样本。
后向损失:给定一个 positive,从批次中的所有 anchor 中找到相似度最高的样本。
例如,对于问答对,前向损失为给定问题找到答案,而后向损失为给定答案找到问题。这种损失在对称任务中很常见,例如语义文本相似度。
缓存修改允许使用大批量(这能提供更好的训练信号),同时保持恒定的内存使用量,让您可以用常规硬件达到最佳训练信号。
注意:如果您传递三元组,负样本条目将被忽略。只为 anchor 搜索 positive。
- 参数:
model – SentenceTransformer 模型
scale – 相似度函数的输出乘以 scale 值。在一些文献中,缩放参数被称为温度,它是 scale 的倒数。简而言之:scale = 1 / temperature,所以 scale=20.0 等价于 temperature=0.05。
similarity_fct – 句子嵌入之间的相似度函数。默认为 cos_sim。也可以设置为点积(然后将 scale 设置为 1)
mini_batch_size – 前向传递的小批量大小,这表示训练和评估期间实际使用的内存量。小批量大小越大,训练的内存效率越高,但训练速度会越慢。建议将其设置为您的 GPU 内存允许的最高值。默认值为 32。
gather_across_devices – 如果为 True,则在计算损失之前跨所有设备收集嵌入。在多 GPU 上训练时推荐使用,因为它允许更大的批处理大小,但可能会因通信开销而减慢训练速度,并可能导致内存不足错误。
show_progress_bar – 如果为 True,则在训练期间显示小批量的进度条。默认为 False。
- 要求
(锚点, 正例) 对
应与大批量一起使用以获得卓越性能,但训练时间比非缓存版本慢。
- 输入
文本
标签
(锚点, 正例) 对
无
- 建议
使用
BatchSamplers.NO_DUPLICATES(文档) 以确保批内负样本不是锚点或正样本的副本。
- 关系
类似于
MultipleNegativesRankingLoss,但增加了额外的对称损失项和缓存机制。受
CachedMultipleNegativesRankingLoss启发,并为对称损失计算进行了调整。
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], }) loss = losses.CachedMultipleNegativesSymmetricRankingLoss(model, mini_batch_size=32) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
参考文献
Efficient Natural Language Response Suggestion for Smart Reply, 第 4.4 节:https://arxiv.org/pdf/1705.00652.pdf
在内存受限设置下扩展深度对比学习批处理大小:https://arxiv.org/pdf/2101.06983.pdf
SoftmaxLoss
- class sentence_transformers.losses.SoftmaxLoss(model: SentenceTransformer, sentence_embedding_dimension: int, num_labels: int, concatenation_sent_rep: bool = True, concatenation_sent_difference: bool = True, concatenation_sent_multiplication: bool = False, loss_fct: Callable = CrossEntropyLoss())[源代码]
此损失函数在我们的 SBERT 出版物 (https://arxiv.org/abs/1908.10084) 中用于在 NLI 数据上训练 SentenceTransformer 模型。它在两个 Transformer 网络的输出之上添加了一个 softmax 分类器。
根据 https://arxiv.org/abs/2004.09813,
MultipleNegativesRankingLoss是一个替代损失函数,通常能产生更好的结果。- 参数:
model (SentenceTransformer) – SentenceTransformer 模型。
sentence_embedding_dimension (int) – 句子嵌入的维度。
num_labels (int) – 不同标签的数量。
concatenation_sent_rep (bool) – 是否为 softmax 分类器连接向量 u, v。默认为 True。
concatenation_sent_difference (bool) – 是否为 softmax 分类器添加 abs(u-v)。默认为 True。
concatenation_sent_multiplication (bool) – 是否为 softmax 分类器添加 u*v。默认为 False。
loss_fct (Callable) – 自定义 pytorch 损失函数。如果未设置,则使用 nn.CrossEntropyLoss()。默认为 nn.CrossEntropyLoss()。
参考文献
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks: https://arxiv.org/abs/1908.10084
- 要求
带有类别标签的句子对
- 输入
文本
标签
(句子_A, 句子_B) 对
类别
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "sentence1": [ "A person on a horse jumps over a broken down airplane.", "A person on a horse jumps over a broken down airplane.", "A person on a horse jumps over a broken down airplane.", "Children smiling and waving at camera", ], "sentence2": [ "A person is training his horse for a competition.", "A person is at a diner, ordering an omelette.", "A person is outdoors, on a horse.", "There are children present.", ], "label": [1, 2, 0, 0], }) loss = losses.SoftmaxLoss(model, model.get_sentence_embedding_dimension(), num_labels=3) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
TripletLoss
- class sentence_transformers.losses.TripletLoss(model: ~sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function TripletDistanceMetric.<lambda>>, triplet_margin: float = 5)[源代码]
这个类实现了三元组损失。给定一个 (anchor, positive, negative) 的三元组,损失会最小化 anchor 和 positive 之间的距离,同时最大化 anchor 和 negative 之间的距离。它计算以下损失函数:
loss = max(||anchor - positive|| - ||anchor - negative|| + margin, 0).边距 (Margin) 是一个重要的超参数,需要相应地进行调整。
- 参数:
model – SentenceTransformer 模型
distance_metric – 用于计算两个嵌入之间距离的函数。TripletDistanceMetric 类包含可以使用的常见距离度量。
triplet_margin – 负样本与 anchor 的距离应该比正样本与 anchor 的距离至少远这么多。
参考文献
- 要求
(锚点, 正例, 负例) 三元组
- 输入
文本
标签
(锚点, 正例, 负例) 三元组
无
示例
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset model = SentenceTransformer("microsoft/mpnet-base") train_dataset = Dataset.from_dict({ "anchor": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to the office."], "negative": ["It's quite rainy, sadly.", "She walked to the store."], }) loss = losses.TripletLoss(model=model) trainer = SentenceTransformerTrainer( model=model, train_dataset=train_dataset, loss=loss, ) trainer.train()
DistillKLDivLoss
- class sentence_transformers.losses.DistillKLDivLoss(model: SentenceTransformer, similarity_fct=<function pairwise_dot_score>, temperature: float = 1.0)[源代码]
计算从学生模型和教师模型的相似度分数派生出的概率分布之间的 KL 散度损失。默认情况下,使用点积计算相似度。此损失专为知识蒸馏设计,其中较小的学生模型从更强大的教师模型中学习。
该损失从教师相似度分数计算 softmax 概率,从学生模型计算 log-softmax 概率,然后计算这些分布之间的 KL 散度。
- 参数:
model – SentenceTransformer 模型(学生模型)
similarity_fct – 学生模型使用哪种相似度函数
temperature – 用于软化概率分布的温度参数(温度越高 = 分布越软)。温度为 1.0 时不缩放分数。注意:在 v5.0.1 版本中,默认温度从 2.0 更改为 1.0。
参考文献
更多详情,请参考 https://arxiv.org/abs/2010.11386
- 要求
(query, positive, negative_1, ..., negative_n) 样本
包含教师模型在 query-positive 和 query-negative 对之间分数的标签
- 输入
文本
标签
(查询, 正例, 负例)
[Teacher(query, positive), Teacher(query, negative)]
(查询, 正例, 负例_1, ..., 负例_n)
[Teacher(query, positive), Teacher(query, negative_i)...]
- 关系
与
MarginMSELoss类似,但使用 KL 散度(KL divergence)而非均方误差(MSE)。更适用于需要保留排序信息的蒸馏任务。
示例
使用教师模型计算相似度分数以进行蒸馏。
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset import torch student_model = SentenceTransformer("microsoft/mpnet-base") teacher_model = SentenceTransformer("all-mpnet-base-v2") train_dataset = Dataset.from_dict({ "query": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to work."], "negative": ["It's very cold.", "She walked to the store."], }) def compute_labels(batch): emb_queries = teacher_model.encode(batch["query"]) emb_positives = teacher_model.encode(batch["positive"]) emb_negatives = teacher_model.encode(batch["negative"]) pos_scores = teacher_model.similarity_pairwise(emb_queries, emb_positives) neg_scores = teacher_model.similarity_pairwise(emb_queries, emb_negatives) # Stack the scores for positive and negative pairs return { "label": torch.stack([pos_scores, neg_scores], dim=1) } train_dataset = train_dataset.map(compute_labels, batched=True) loss = losses.DistillKLDivLoss(student_model) trainer = SentenceTransformerTrainer(model=student_model, train_dataset=train_dataset, loss=loss) trainer.train()
使用多个负样本。
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses from datasets import Dataset import torch student_model = SentenceTransformer("microsoft/mpnet-base") teacher_model = SentenceTransformer("all-mpnet-base-v2") train_dataset = Dataset.from_dict( { "query": ["It's nice weather outside today.", "He drove to work."], "positive": ["It's so sunny.", "He took the car to work."], "negative1": ["It's very cold.", "She walked to the store."], "negative2": ["Its rainy", "She took the bus"], } ) def compute_labels(batch): emb_queries = teacher_model.encode(batch["query"]) emb_positives = teacher_model.encode(batch["positive"]) emb_negatives1 = teacher_model.encode(batch["negative1"]) emb_negatives2 = teacher_model.encode(batch["negative2"]) pos_scores = teacher_model.similarity_pairwise(emb_queries, emb_positives) neg_scores1 = teacher_model.similarity_pairwise(emb_queries, emb_negatives1) neg_scores2 = teacher_model.similarity_pairwise(emb_queries, emb_negatives2) # Stack the scores for positive and multiple negative pairs return { "label": torch.stack([pos_scores, neg_scores1, neg_scores2], dim=1) } train_dataset = train_dataset.map(compute_labels, batched=True) loss = losses.DistillKLDivLoss(student_model) trainer = SentenceTransformerTrainer(model=student_model, train_dataset=train_dataset, loss=loss) trainer.train()