CT (批内负例)
Carlsson 等人在 《Semantic Re-Tuning With Contrastive Tension (CT)》 一文中提出了一种仅需句子的无监督学习方法,用于生成句子嵌入。
背景
在训练过程中,CT 构建两个独立的编码器(‘Model1’ 和 ‘Model2’),并共享初始参数来编码一个句子对。如果 Model1 和 Model2 编码的是同一个句子,那么这两个句子嵌入的点积应该很大。如果 Model1 和 Model2 编码的是不同的句子,那么它们的点积应该很小。
在原始的 CT 论文中,使用了特殊创建的批次。我们实现了一个改进版本,它使用批内负采样 (in-batch negative sampling):Model1 和 Model2 都对同一组句子进行编码。我们最大化匹配索引(即 Model1(S_i) 和 Model2(S_i))的分数,同时最小化不同索引(即 i != j 时的 Model1(S_i) 和 Model2(S_j))的分数。
与 Carlsson 等人提出的原始损失函数相比,使用批内负采样能提供更强的训练信号。
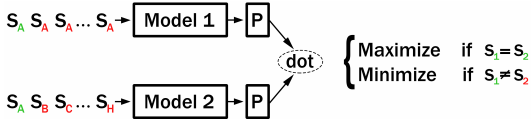
训练后,模型2 将用于推理,通常性能更佳。
性能
在一些初步实验中,我们比较了在 STSbenchmark 数据集(使用来自维基百科的 100 万个句子进行训练)和 Quora 重复问题数据集(使用来自 Quora 的问题进行训练)上的性能。
| 方法 | STSb (Spearman) | Quora-Duplicate-Question (平均精度) |
|---|---|---|
| CT | 75.7 | 36.5 |
| CT (批内负例) | 78.5 | 40.1 |
注意:我们使用的是本仓库中提供的代码,而非作者的官方代码。
从句子文件进行 CT
train_ct-improved_from_file.py 从提供的文本文件中加载句子。该文本文件应为每行一个句子。
SimCSE 将使用这些句子进行训练。检查点每 500 步保存到输出文件夹中。
更多训练示例
train_stsb_ct-improved.py:此示例使用来自维基百科的 100 万个句子进行 CT 训练。它在 STSbenchmark 数据集 上评估性能。
train_askubuntu_ct-improved.py:此示例在 AskUbuntu Questions 数据集 上进行训练,该数据集包含来自 AskUbuntu Stackexchange 论坛的问题。