领域自适应
领域自适应的目标是让文本嵌入模型适应您特定的文本领域,而无需标记的训练数据。
领域自适应仍然是一个活跃的研究领域,目前尚无完美的解决方案。然而,在我们最近的两篇论文 TSDAE 和 GPL 中,我们评估了几种使文本嵌入模型适应您特定领域的方法。您可以在我关于无监督领域自适应的演讲中找到这些方法的概述。
领域自适应 vs. 无监督学习
虽然存在无监督文本嵌入学习的方法,但它们通常表现不佳:它们无法真正学习特定领域的概念。
一个更好的方法是领域自适应:您拥有一个来自特定领域的未标记语料库,以及一个现有的已标记语料库。您可以在这里找到许多合适的已标记训练数据集:嵌入模型数据集集合
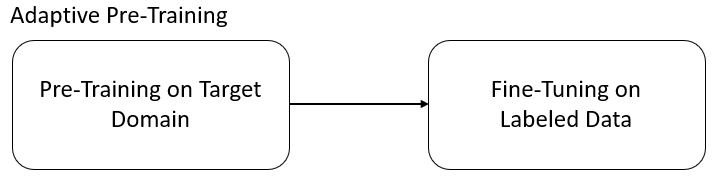
自适应预训练
当使用自适应预训练时,您首先在目标语料库上使用例如掩码语言建模 (Masked Language Modeling) 或 TSDAE 进行预训练,然后在现有的训练数据集上进行微调(参见嵌入模型数据集集合)。
在我们的论文 TSDAE 中,我们评估了几种领域自适应方法在 4 个特定领域的句子嵌入任务上的表现。
| 方法 | AskUbuntu | CQADupStack | SciDocs | 平均值 | |
|---|---|---|---|---|---|
| 零样本模型 | 54.5 | 12.9 | 72.2 | 69.4 | 52.3 |
| TSDAE | 59.4 | 14.4 | 74.5 | 77.6 | 56.5 |
| MLM (掩码语言建模) | 60.6 | 14.3 | 71.8 | 76.9 | 55.9 |
| CT (对比张力) | 56.4 | 13.4 | 72.4 | 69.7 | 53.0 |
| SimCSE | 56.2 | 13.1 | 71.4 | 68.9 | 52.4 |
正如我们所见,当您首先在特定语料库上进行预训练,然后在提供的已标记训练数据上进行微调时,性能最多可以提高 8 个点。
在 GPL 中,我们评估了这些方法用于语义搜索:给定一个简短的查询,找到相关的段落。在这里,性能最多可以提高 10 个点。
| 方法 | FiQA | SciFact | BioASQ | TREC-COVID | CQADupStack | Robust04 | 平均值 |
|---|---|---|---|---|---|---|---|
| 零样本模型 | 26.7 | 57.1 | 52.9 | 66.1 | 29.6 | 39.0 | 45.2 |
| TSDAE | 29.3 | 62.8 | 55.5 | 76.1 | 31.8 | 39.4 | 49.2 |
| MLM (掩码语言建模) | 30.2 | 60.0 | 51.3 | 69.5 | 30.4 | 38.8 | 46.7 |
| ICT (信息和通信技术) | 27.0 | 58.3 | 55.3 | 69.7 | 31.3 | 37.4 | 46.5 |
| SimCSE | 26.7 | 55.0 | 53.2 | 68.3 | 29.0 | 37.9 | 45.0 |
| CD (对比去噪) | 27.0 | 62.7 | 47.7 | 65.4 | 30.6 | 34.5 | 44.7 |
| CT (对比张力) | 28.3 | 55.6 | 49.9 | 63.8 | 30.5 | 35.9 | 44.0 |
自适应预训练的一大缺点是计算开销高,因为您必须首先在语料库上运行预训练,然后在已标记的训练数据集上进行监督学习。已标记的训练数据集可能非常大(例如,all-*-v1 模型是在超过 10 亿个训练对上训练的)。
GPL:生成式伪标签
GPL 克服了上述问题:它可以应用于微调过的模型之上。因此,您可以使用预训练模型之一,并将其调整到您的特定领域。

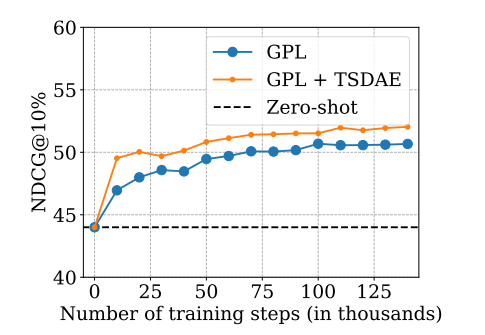
训练时间越长,模型效果越好。在我们的实验中,我们在 V100-GPU 上训练模型大约 1 天。GPL 可以与自适应预训练相结合,这可以带来另一次性能提升。
GPL 步骤
GPL 分三个阶段工作:
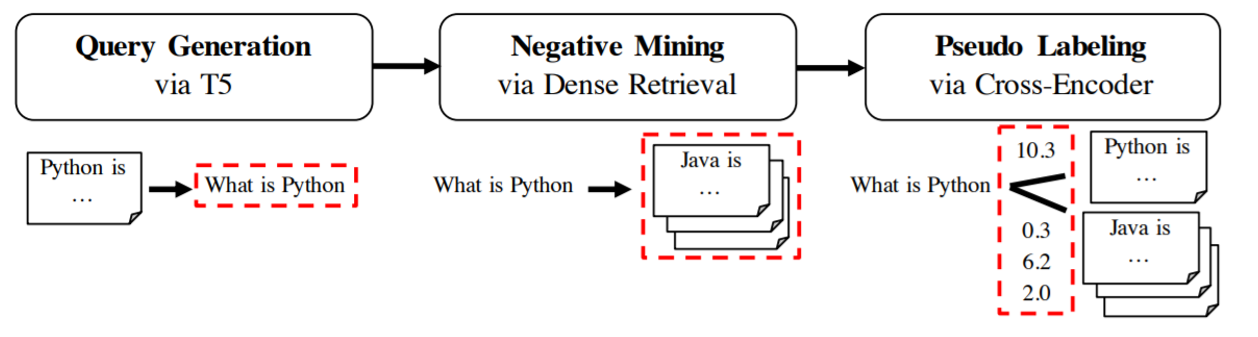
查询生成:对于我们领域中的给定文本,我们首先使用 T5 模型为给定文本生成一个可能的查询。例如,当您的文本是“Python 是一种高级通用编程语言”时,模型可能会生成一个查询,如“什么是 Python”。您可以在我们的 doc2query-hub 上找到各种查询生成器。
负例挖掘:接下来,对于生成的查询“什么是 Python”,我们在我们的语料库中挖掘负例段落,即与查询相似但用户不会认为相关的段落。这样一个负例段落可能是“Java 是一种高级、基于类、面向对象的编程语言”。我们使用密集检索来进行这种挖掘,即我们使用现有的文本嵌入模型之一,为给定的查询检索相关段落。
伪标签:在负例挖掘步骤中,我们可能会检索到一个实际上与查询相关的段落(比如“什么是 Python”的另一个定义)。为了克服这个问题,我们使用交叉编码器 (Cross-Encoder)来为所有(查询,段落)对打分。
训练:一旦我们有了三元组*(生成的查询,正例段落,挖掘出的负例段落)*以及 *(查询,正例)*和 *(查询,负例)*的交叉编码器分数,我们就可以开始使用 MarginMSELoss 训练文本嵌入模型。
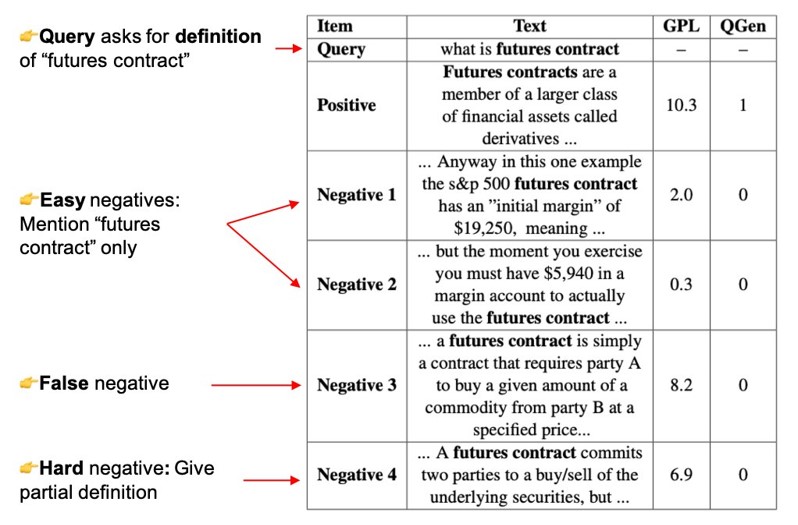
伪标签步骤非常重要,它导致了性能相较于之前的方法 QGen 有所提升,QGen 仅将段落视为正例 (1) 或负例 (0)。如下图所示,对于一个生成的查询(“what is futures contract”),负例挖掘步骤检索到的段落与生成的查询部分相关或高度相关。使用 MarginMSELoss 和交叉编码器,我们可以识别这些段落,并教文本嵌入模型这些段落也与给定的查询相关。
下表概述了 GPL 与自适应预训练(MLM 和 TSDAE)的比较。如前所述,GPL 可以与自适应预训练相结合。
| 方法 | FiQA | SciFact | BioASQ | TREC-COVID | CQADupStack | Robust04 | 平均值 |
|---|---|---|---|---|---|---|---|
| 零样本模型 | 26.7 | 57.1 | 52.9 | 66.1 | 29.6 | 39.0 | 45.2 |
| TSDAE + GPL | 33.3 | 67.3 | 62.8 | 74.0 | 35.1 | 42.1 | 52.4 |
| GPL (生成式伪标签) | 33.1 | 65.2 | 61.6 | 71.7 | 34.4 | 42.1 | 51.4 |
| TSDAE | 29.3 | 62.8 | 55.5 | 76.1 | 31.8 | 39.4 | 49.2 |
| MLM (掩码语言建模) | 30.2 | 60.0 | 51.3 | 69.5 | 30.4 | 38.8 | 46.7 |
GPL 代码
您可以在这里找到 GPL 的代码:https://github.com/UKPLab/gpl
我们简化了代码的使用,您只需传入您的语料库,其他一切都由训练代码处理。
引用
如果您觉得这些资源有帮助,欢迎引用我们的论文。
@inproceedings{wang-2021-TSDAE,
title = "TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning",
author = "Wang, Kexin and Reimers, Nils and Gurevych, Iryna",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
pages = "671--688",
url = "https://arxiv.org/abs/2104.06979",
}
@inproceedings{wang-2021-GPL,
title = "GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval",
author = "Wang, Kexin and Thakur, Nandan and Reimers, Nils and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2112.07577",
month = "12",
year = "2021",
url = "https://arxiv.org/abs/2112.07577",
}