语义文本相似度
语义文本相似度(Semantic Textual Similarity, STS)旨在为两个文本的相似度打分。在本示例中,我们使用 stsb 数据集作为训练数据来微调我们的模型。请参阅以下示例脚本,了解如何在 STS 数据上调整 SentenceTransformer。
training_stsbenchmark.py - 此示例展示了如何通过使用预训练的 Transformer 模型(例如
distilbert-base-uncased)和池化层来从头开始创建一个 SentenceTransformer 模型。training_stsbenchmark_continue_training.py - 此示例展示了如何在一个之前已创建并训练过的 SentenceTransformer 模型(例如
all-mpnet-base-v2)上继续使用 STS 数据进行训练。
您也可以为此任务训练和使用 CrossEncoder 模型。详情请参阅Cross Encoder > 训练示例 > 语义文本相似度。
训练数据
在 STS 中,我们有句子对,并附有指示其相似度的分数。在原始的 STSbenchmark 数据集中,分数范围从 0 到 5。我们在 stsb 中将这些分数归一化到 0 到 1 的范围,因为 CosineSimilarityLoss 需要这样做,正如您在损失函数概览中所见。
以下是我们的训练数据的简化版本
from datasets import Dataset
sentence1_list = ["My first sentence", "Another pair"]
sentence2_list = ["My second sentence", "Unrelated sentence"]
labels_list = [0.8, 0.3]
train_dataset = Dataset.from_dict({
"sentence1": sentence1_list,
"sentence2": sentence2_list,
"label": labels_list,
})
# => Dataset({
# features: ['sentence1', 'sentence2', 'label'],
# num_rows: 2
# })
print(train_dataset[0])
# => {'sentence1': 'My first sentence', 'sentence2': 'My second sentence', 'label': 0.8}
print(train_dataset[1])
# => {'sentence1': 'Another pair', 'sentence2': 'Unrelated sentence', 'label': 0.3}
在上述脚本中,我们直接加载 stsb 数据集
from datasets import load_dataset
train_dataset = load_dataset("sentence-transformers/stsb", split="train")
# => Dataset({
# features: ['sentence1', 'sentence2', 'score'],
# num_rows: 5749
# })
损失函数
我们使用 CosineSimilarityLoss 作为我们的损失函数。
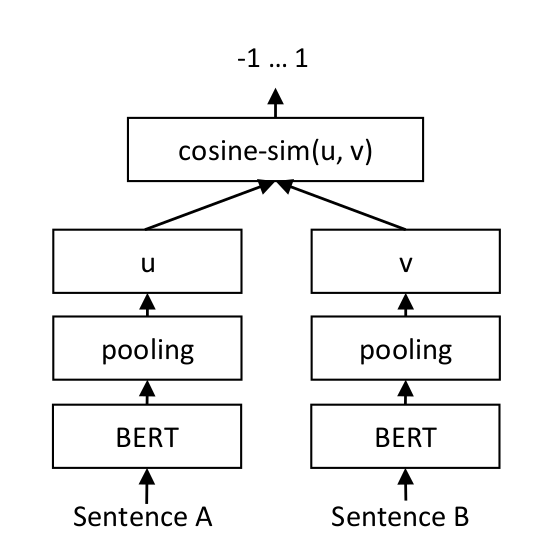
对于每个句子对,我们将句子 A 和句子 B 传递给基于 BERT 的模型,从而得到嵌入向量 u 和 v。我们使用余弦相似度计算这些嵌入向量的相似度,并将结果与真实的相似度分数进行比较。请注意,这两个句子是通过同一个模型而不是两个独立的模型进行处理的。具体来说,对于相似的文本,余弦相似度被最大化;而对于不相似的文本,余弦相似度被最小化。这使得我们的模型能够被微调并识别句子的相似性。
更多详情,请参阅 Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks。
CoSENTLoss 和 AnglELoss 是 CosineSimilarityLoss 的更现代的变体,它们接受相同的数据格式,即一个句子对和一个范围在 0.0 到 1.0 之间的相似度分数。非正式实验表明,这两种损失函数生成的模型比 CosineSimilarityLoss 更强大。