MS MARCO
MS MARCO Passage Ranking 是一个用于训练信息检索模型的大型数据集。它包含了约 50 万条来自 Bing 搜索引擎的真实搜索查询,以及能够回答这些查询的相关文本段落。
本页展示了如何在该数据集上**训练**稀疏编码器模型(更确切地说,是 Splade 模型),以便根据查询(关键词、短语或问题)来搜索文本段落。
如果您对如何使用这些模型感兴趣,请参阅应用 - 检索与重排。
我们提供了**预训练模型**,您可以直接使用,无需自己训练模型。更多信息,请参阅:预训练模型。
本页描述了在 MS MARCO 数据集上**训练 Splade 模型**的一种策略。
SparseMultipleNegativesRankingLoss
训练代码:train_splade_msmarco_mnrl.py
当我们使用 SparseMultipleNegativesRankingLoss 时,我们提供三元组:(query, positive_passage, negative_passage),其中 positive_passage 是与查询相关的段落,而 negative_passage 是与查询不相关的段落。我们计算语料库中所有查询、正例段落和负例段落的嵌入,然后优化以下目标:(query, positive_passage) 对在向量空间中必须相近,而 (query, negative_passage) 在向量空间中应该相距较远。
为了进一步改善训练效果,我们使用**批内负样本 (in-batch negatives)**
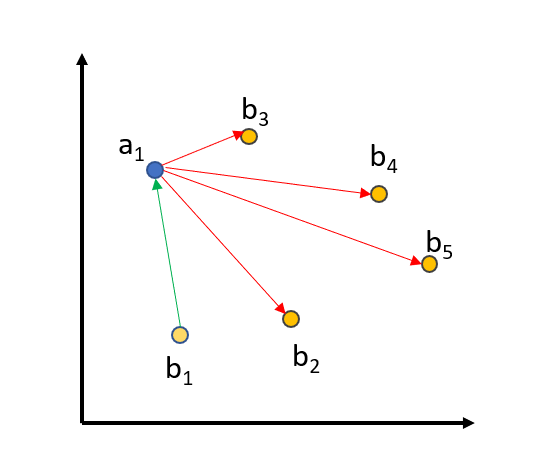
我们将所有的 queries(查询)、positive_passages(正例段落)和 negative_passages(负例段落)嵌入到向量空间中。匹配的 (query_i, positive_passage_i) 应该距离相近,而一个 query 与批次中所有其他三元组的(正例/负例)段落之间应该有很大的距离。对于大小为 64 的批次,我们将一个查询与 64+64=128 个段落进行比较,其中只有一个段落应该距离相近,而其他 127 个段落应该在向量空间中相距较远。
一种**改进训练**的方法是选择非常好的负样本,也称为**困难负样本 (hard negative)**:负样本应该看起来与正例段落非常相似,但与查询不相关。
我们通过以下方式找到这些困难负样本:我们使用现有的检索系统(例如,词法搜索和其他双编码器检索系统),并为每个查询找到最相关的段落。然后,我们使用一个强大的 cross-encoder/ms-marco-MiniLM-L6-v2 Cross-Encoder 来为找到的 (query, passage) 对打分。我们在我们的 MS MARCO Mined Triplet 数据集集合中为 1.6 亿个这样的对提供了分数。
对于 SparseMultipleNegativesRankingLoss,我们必须确保在三元组 (query, positive_passage, negative_passage) 中,negative_passage 确实与查询不相关。遗憾的是,MS MARCO 数据集**高度冗余**,尽管平均每个查询只有一个段落被标记为相关,但实际上它包含了许多人类会认为是相关的段落。我们必须确保这些段落**不被当作负样本**:我们通过确保相关段落和挖掘出的困难负样本之间的 CrossEncoder 分数存在一定的阈值来实现这一点。默认情况下,我们设置阈值为 3:如果 (query, positive_passage) 从 CrossEncoder 获得的分数为 9,那么我们只会考虑来自 CrossEncoder 分数低于 6 的负样本。这个阈值确保了我们真正在三元组中使用了负样本。
您可以通过访问 MS MARCO Mined Triplet 数据集集合中的任何一个数据集并使用 triplet-hard 子集来找到这些数据。在所有数据集中,这涉及 1.757 亿个三元组。原始数据可以在这里找到。在我们的示例中,我们只使用了原始的 triplet 数据集,因为它
from datasets import load_dataset
dataset_size = 100_000 # We only use the first 100k samples for training
print("The dataset has not been fully stored as texts on disk yet. We will do this now.")
corpus = load_dataset("sentence-transformers/msmarco", "corpus", split="train")
corpus = dict(zip(corpus["passage_id"], corpus["passage"]))
queries = load_dataset("sentence-transformers/msmarco", "queries", split="train")
queries = dict(zip(queries["query_id"], queries["query"]))
dataset = load_dataset("sentence-transformers/msmarco", "triplets", split="train")
dataset = dataset.select(range(dataset_size))
def id_to_text_map(batch):
return {
"query": [queries[qid] for qid in batch["query_id"]],
"positive": [corpus[pid] for pid in batch["positive_id"]],
"negative": [corpus[pid] for pid in batch["negative_id"]],
}
dataset = dataset.map(id_to_text_map, batched=True, remove_columns=["query_id", "positive_id", "negative_id"])
dataset = dataset.train_test_split(test_size=10_000)
train_dataset = dataset["train"]
eval_dataset = dataset["test"]