加速推理
Sentence Transformers 支持 3 种后端来执行 Cross Encoder 模型的推理,每种后端都有其自身的优化来加速推理。
PyTorch
PyTorch 后端是 Cross Encoders 的默认后端。如果您不指定设备,它将使用“cuda”、“mps”和“cpu”中最强的可用选项。其默认用法如下:
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2")
query = "Which planet is known as the Red Planet?"
passages = [
"Venus is often called Earth's twin because of its similar size and proximity.",
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet."
]
scores = model.predict([(query, passage) for passage in passages])
print(scores)
如果您正在使用 GPU,可以使用以下选项来加速推理:
Float32(fp32,全精度)是 torch 中的默认浮点格式,而 float16(fp16,半精度)是一种降精度浮点格式,可以在 GPU 上以极小的模型精度损失加速推理。要使用它,您可以在初始化时指定 torch_dtype,或者在初始化后的模型上调用 model.half()。
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2", model_kwargs={"torch_dtype": "float16"})
# or: model.half()
query = "Which planet is known as the Red Planet?"
passages = [
"Venus is often called Earth's twin because of its similar size and proximity.",
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet."
]
scores = model.predict([(query, passage) for passage in passages])
print(scores)
Bfloat16 (bf16) 类似于 fp16,但比 fp16 更多地保留了 fp32 的原始精度。要使用它,您可以在初始化时指定 torch_dtype,或者在初始化后的模型上调用 model.bfloat16()。
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2", model_kwargs={"torch_dtype": "bfloat16"})
# or: model.bfloat16()
query = "Which planet is known as the Red Planet?"
passages = [
"Venus is often called Earth's twin because of its similar size and proximity.",
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet."
]
scores = model.predict([(query, passage) for passage in passages])
print(scores)
ONNX
ONNX 可用于通过将模型转换为 ONNX 格式并使用 ONNX Runtime 运行模型来加速推理。要使用 ONNX 后端,您必须通过 onnx 或 onnx-gpu 扩展安装 Sentence Transformers,分别用于 CPU 或 GPU 加速。
pip install sentence-transformers[onnx-gpu]
# or
pip install sentence-transformers[onnx]
要将模型转换为 ONNX 格式,您可以使用以下代码:
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2", backend="onnx")
query = "Which planet is known as the Red Planet?"
passages = [
"Venus is often called Earth's twin because of its similar size and proximity.",
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet."
]
scores = model.predict([(query, passage) for passage in passages])
print(scores)
如果模型路径或仓库中已包含 ONNX 格式的模型,Sentence Transformers 会自动使用它。否则,它会将模型转换为 ONNX 格式。
注意
如果您希望在 Sentence Transformers 之外使用 ONNX 模型,您可能需要应用您选择的激活函数(例如 Sigmoid)以获得与 Sentence Transformers 中的 Cross Encoder 相同的结果。
所有通过 model_kwargs 传递的关键字参数都将传递给 ORTModelForSequenceClassification.from_pretrained。一些值得注意的参数包括:
provider:用于加载模型的 ONNX Runtime 提供程序,例如"CPUExecutionProvider"。有关可能的提供程序,请参阅 https://runtime.onnx.org.cn/docs/execution-providers/。如果未指定,将使用最强的提供程序(例如"CUDAExecutionProvider")。file_name:要加载的 ONNX 文件的名称。如果未指定,将默认为"model.onnx"或"onnx/model.onnx"。此参数对于指定优化或量化模型很有用。export:一个布尔标志,指定是否将导出模型。如果未提供,并且模型仓库或目录中尚不包含 ONNX 模型,则export将被设置为True。
提示
强烈建议保存导出的模型,以防止每次运行代码时都重新导出。如果您的模型是本地的,可以通过调用 model.save_pretrained() 来实现:
model = CrossEncoder("path/to/my/model", backend="onnx")
model.save_pretrained("path/to/my/model")
或者,如果您的模型来自 Hugging Face Hub,可以使用 model.push_to_hub():
model = CrossEncoder("Alibaba-NLP/gte-reranker-modernbert-base", backend="onnx")
model.push_to_hub("Alibaba-NLP/gte-reranker-modernbert-base", create_pr=True)
优化 ONNX 模型
ONNX 模型可以使用 Optimum 进行优化,从而在 CPU 和 GPU 上都能加速。为此,您可以使用 export_optimized_onnx_model() 函数,它会将优化后的模型保存在您指定的目录或模型仓库中。它需要:
model: 一个使用 ONNX 后端加载的 Sentence Transformer、Sparse Encoder 或 Cross Encoder 模型。optimization_config:"O1"、"O2"、"O3"或"O4",代表来自AutoOptimizationConfig的优化级别,或一个OptimizationConfig实例。model_name_or_path: 用于保存优化后模型文件的路径,或者如果您想将其推送到 Hugging Face Hub,则为仓库名称。push_to_hub: (可选)一个布尔值,用于将优化后的模型推送到 Hugging Face Hub。create_pr: (可选)一个布尔值,用于在推送到 Hugging Face Hub 时创建一个拉取请求(pull request)。当您没有仓库的写权限时很有用。file_suffix:(可选)在保存模型时附加到模型名称的字符串。如果未指定,将使用优化级别的名称字符串,或者如果优化配置不只是一个字符串优化级别,则仅使用"optimized"。
请参阅此示例,了解如何使用优化级别 3(基础和扩展通用优化、transformers 特定融合、快速 Gelu 近似)导出模型:
仅优化一次
from sentence_transformers import CrossEncoder, export_optimized_onnx_model
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2", backend="onnx")
export_optimized_onnx_model(
model=model,
optimization_config="O3",
model_name_or_path="cross-encoder/ms-marco-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
在拉取请求合并之前
from sentence_transformers import CrossEncoder
pull_request_nr = 2 # TODO: Update this to the number of your pull request
model = CrossEncoder(
"cross-encoder/ms-marco-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
revision=f"refs/pr/{pull_request_nr}"
)
拉取请求合并后
from sentence_transformers import CrossEncoder
model = CrossEncoder(
"cross-encoder/ms-marco-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
)
仅优化一次
from sentence_transformers import CrossEncoder, export_optimized_onnx_model
model = CrossEncoder("path/to/my/mpnet-legal-finetuned", backend="onnx")
export_optimized_onnx_model(
model=model, optimization_config="O3", model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
优化后
from sentence_transformers import CrossEncoder
model = CrossEncoder(
"path/to/my/mpnet-legal-finetuned",
backend="onnx",
model_kwargs={"file_name": "onnx/model_O3.onnx"},
)
量化 ONNX 模型
ONNX 模型可以使用 Optimum 量化到 int8 精度,从而在 CPU 上实现更快的推理。为此,您可以使用 export_dynamic_quantized_onnx_model() 函数,它会将量化后的模型保存在您指定的目录或模型仓库中。动态量化与静态量化不同,不需要校准数据集。它需要:
model: 一个使用 ONNX 后端加载的 Sentence Transformer、Sparse Encoder 或 Cross Encoder 模型。quantization_config:"arm64"、"avx2"、"avx512"或"avx512_vnni",代表来自AutoQuantizationConfig的量化配置,或一个QuantizationConfig实例。model_name_or_path: 用于保存量化后模型文件的路径,或者如果您想将其推送到 Hugging Face Hub,则为仓库名称。push_to_hub: (可选)一个布尔值,用于将量化后的模型推送到 Hugging Face Hub。create_pr: (可选)一个布尔值,用于在推送到 Hugging Face Hub 时创建一个拉取请求(pull request)。当您没有仓库的写权限时很有用。file_suffix:(可选)在保存模型时附加到模型名称的字符串。如果未指定,将使用"qint8_quantized"。
在我的 CPU 上,每个默认的量化配置("arm64"、"avx2"、"avx512"、"avx512_vnni")都带来了大致相当的速度提升。
请参阅此示例,了解如何使用 avx512_vnni 将模型量化为 int8:
仅量化一次
from sentence_transformers import CrossEncoder, export_dynamic_quantized_onnx_model
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2", backend="onnx")
export_dynamic_quantized_onnx_model(
model=model,
quantization_config="avx512_vnni",
model_name_or_path="sentence-transformers/cross-encoder/ms-marco-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
在拉取请求合并之前
from sentence_transformers import CrossEncoder
pull_request_nr = 2 # TODO: Update this to the number of your pull request
model = CrossEncoder(
"cross-encoder/ms-marco-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
revision=f"refs/pr/{pull_request_nr}",
)
拉取请求合并后
from sentence_transformers import CrossEncoder
model = CrossEncoder(
"cross-encoder/ms-marco-MiniLM-L6-v2",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
)
仅量化一次
from sentence_transformers import CrossEncoder, export_dynamic_quantized_onnx_model
model = CrossEncoder("path/to/my/mpnet-legal-finetuned", backend="onnx")
export_dynamic_quantized_onnx_model(
model=model, quantization_config="avx512_vnni", model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
量化后
from sentence_transformers import CrossEncoder
model = CrossEncoder(
"path/to/my/mpnet-legal-finetuned",
backend="onnx",
model_kwargs={"file_name": "onnx/model_qint8_avx512_vnni.onnx"},
)
OpenVINO
OpenVINO 通过将模型导出为 OpenVINO 格式,可以在 CPU 上实现加速推理。要使用 OpenVINO 后端,您必须通过 openvino 扩展安装 Sentence Transformers:
pip install sentence-transformers[openvino]
要将模型转换为 OpenVINO 格式,您可以使用以下代码:
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2", backend="openvino")
query = "Which planet is known as the Red Planet?"
passages = [
"Venus is often called Earth's twin because of its similar size and proximity.",
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet."
]
scores = model.predict([(query, passage) for passage in passages])
print(scores)
如果模型路径或仓库中已包含 OpenVINO 格式的模型,Sentence Transformers 会自动使用它。否则,它会将模型转换为 OpenVINO 格式。
注意
如果您希望在 Sentence Transformers 之外使用 OpenVINO 模型,您可能需要应用您选择的激活函数(例如 Sigmoid)以获得与 Sentence Transformers 中的 Cross Encoder 相同的结果。
model_kwargs 传递的关键字参数都将传递给 OVBaseModel.from_pretrained()。一些值得注意的参数包括:file_name:要加载的 ONNX 文件的名称。如果未指定,将默认为"openvino_model.xml"或"openvino/openvino_model.xml"。此参数对于指定优化或量化模型很有用。export:一个布尔标志,指定是否将导出模型。如果未提供,并且模型仓库或目录中尚不包含 OpenVINO 模型,则export将被设置为True。
提示
强烈建议保存导出的模型,以防止每次运行代码时都重新导出。如果您的模型是本地的,可以通过调用 model.save_pretrained() 来实现:
model = CrossEncoder("path/to/my/model", backend="openvino")
model.save_pretrained("path/to/my/model")
或者,如果您的模型来自 Hugging Face Hub,可以使用 model.push_to_hub():
model = CrossEncoder("Alibaba-NLP/gte-reranker-modernbert-base", backend="openvino")
model.push_to_hub("Alibaba-NLP/gte-reranker-modernbert-base", create_pr=True)
量化 OpenVINO 模型
OpenVINO 模型可以使用 Optimum Intel 量化到 int8 精度以加速推理。为此,您可以使用 export_static_quantized_openvino_model() 函数,它会将量化后的模型保存在您指定的目录或模型仓库中。训练后静态量化需要:
model: 一个使用 OpenVINO 后端加载的 Sentence Transformer、Sparse Encoder 或 Cross Encoder 模型。quantization_config:(可选)量化配置。此参数接受以下任一类型:None表示默认的 8 位量化,一个表示量化配置的字典,或一个OVQuantizationConfig实例。model_name_or_path: 用于保存量化后模型文件的路径,或者如果您想将其推送到 Hugging Face Hub,则为仓库名称。dataset_name:(可选)用于校准的数据集的名称。如果未指定,则默认为glue数据集中的sst2子集。dataset_config_name: (可选)要加载的数据集的具体配置。dataset_split: (可选)要加载的数据集划分(例如,‘train’、‘test’)。column_name: (可选)数据集中用于校准的列名。push_to_hub: (可选)一个布尔值,用于将量化后的模型推送到 Hugging Face Hub。create_pr: (可选)一个布尔值,用于在推送到 Hugging Face Hub 时创建一个拉取请求(pull request)。当您没有仓库的写权限时很有用。file_suffix:(可选)在保存模型时附加到模型名称的字符串。如果未指定,将使用"qint8_quantized"。
请参阅此示例,了解如何使用静态量化将模型量化为 int8:
仅量化一次
from sentence_transformers import CrossEncoder, export_static_quantized_openvino_model
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L6-v2", backend="openvino")
export_static_quantized_openvino_model(
model=model,
quantization_config=None,
model_name_or_path="cross-encoder/ms-marco-MiniLM-L6-v2",
push_to_hub=True,
create_pr=True,
)
在拉取请求合并之前
from sentence_transformers import CrossEncoder
pull_request_nr = 2 # TODO: Update this to the number of your pull request
model = CrossEncoder(
"cross-encoder/ms-marco-MiniLM-L6-v2",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
revision=f"refs/pr/{pull_request_nr}"
)
拉取请求合并后
from sentence_transformers import CrossEncoder
model = CrossEncoder(
"cross-encoder/ms-marco-MiniLM-L6-v2",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
仅量化一次
from sentence_transformers import CrossEncoder, export_static_quantized_openvino_model
from optimum.intel import OVQuantizationConfig
model = CrossEncoder("path/to/my/mpnet-legal-finetuned", backend="openvino")
quantization_config = OVQuantizationConfig()
export_static_quantized_openvino_model(
model=model, quantization_config=quantization_config, model_name_or_path="path/to/my/mpnet-legal-finetuned"
)
量化后
from sentence_transformers import CrossEncoder
model = CrossEncoder(
"path/to/my/mpnet-legal-finetuned",
backend="openvino",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
基准测试
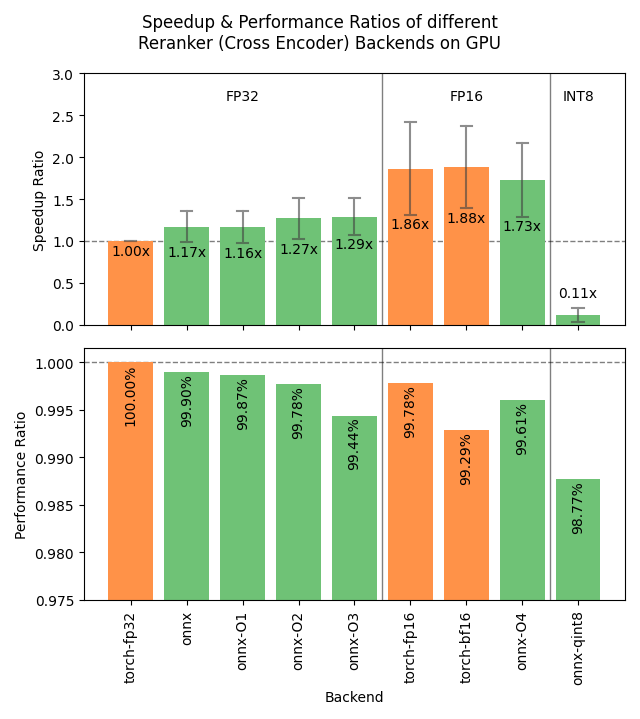
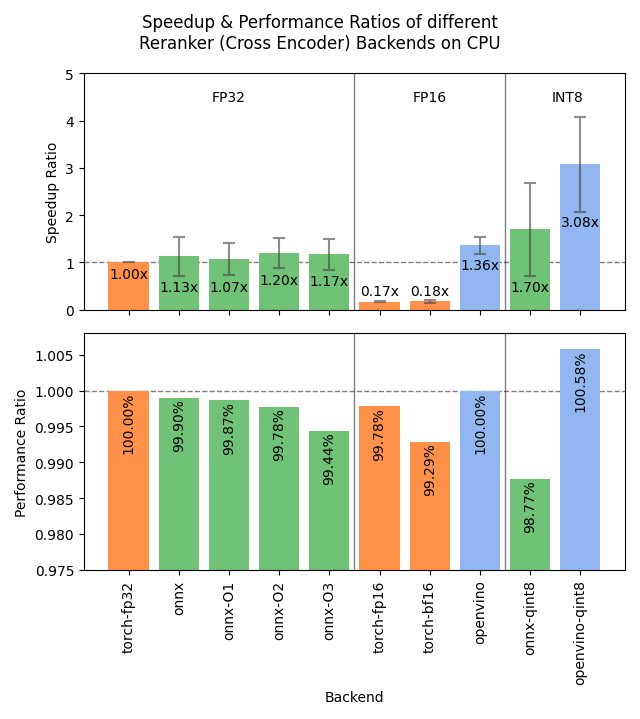
下图显示了不同后端在 GPU 和 CPU 上的基准测试结果。这些结果是综合了 4 种不同大小的模型、3 个数据集和多种批量大小后的平均值。
展开基准测试详情
加速比
- 硬件:RTX 3090 GPU, i7-17300K CPU
-
数据集:GPU 测试使用 2000 个样本,CPU 测试使用 1000 个样本。
-
sentence-transformers/stsb:
sentence1和sentence2列作为配对,平均字符数分别为 38.94 ± 13.97 和 38.96 ± 14.05。 -
sentence-transformers/natural-questions:
query和answer列作为配对,平均字符数分别为 46.99 ± 10.98 和 619.63 ± 345.30。 -
stanfordnlp/imdb: 使用
text列的两种变体:前 100 个字符(100.00 ± 0.00 个字符)和每个样本重复 4 次(16804.25 ± 10178.26 个字符)。
-
sentence-transformers/stsb:
-
模型
- cross-encoder/ms-marco-MiniLM-L6-v2: 2270万参数;批量大小为 16, 32, 64, 128 和 256。
- BAAI/bge-reranker-base: 2.78亿参数;批量大小为 16, 32, 64, 和 128。
- mixedbread-ai/mxbai-rerank-large-v1: 4.35亿参数;批量大小为 8, 16, 32, 和 64。GPU 测试还包括 128 和 256。
- BAAI/bge-reranker-v2-m3: 5.68亿参数;批量大小为 2, 4。GPU 测试还包括 8, 16, 和 32。
-
评估
- 信息检索:基于 NanoBEIR 数据集集合中 MS MARCO 和 NQ 子集的余弦相似度的 NDCG@10,通过 CrossEncoderNanoBEIREvaluator 计算。
-
后端
-
torch-fp32: PyTorch,使用 float32 精度(默认)。 -
torch-fp16: PyTorch,使用 float16 精度,通过model_kwargs={"torch_dtype": "float16"}实现。 -
torch-bf16: PyTorch,使用 bfloat16 精度,通过model_kwargs={"torch_dtype": "bfloat16"}实现。 -
onnx: ONNX,使用 float32 精度,通过backend="onnx"实现。 -
onnx-O1: ONNX,使用 float32 精度和 O1 优化,通过export_optimized_onnx_model(..., optimization_config="O1", ...)和backend="onnx"实现。 -
onnx-O2: ONNX,使用 float32 精度和 O2 优化,通过export_optimized_onnx_model(..., optimization_config="O2", ...)和backend="onnx"实现。 -
onnx-O3: ONNX,使用 float32 精度和 O3 优化,通过export_optimized_onnx_model(..., optimization_config="O3", ...)和backend="onnx"实现。 -
onnx-O4: ONNX,使用 float16 精度和 O4 优化,通过export_optimized_onnx_model(..., optimization_config="O4", ...)和backend="onnx"实现。 -
onnx-qint8: ONNX 使用 "avx512_vnni" 量化到 int8,通过export_dynamic_quantized_onnx_model(..., quantization_config="avx512_vnni", ...)和backend="onnx"实现。不同的量化配置带来了大致相当的速度提升。 -
openvino: OpenVINO,通过backend="openvino"实现。 -
openvino-qint8: OpenVINO,量化到 int8,通过export_static_quantized_openvino_model(..., quantization_config=OVQuantizationConfig(), ...)和backend="openvino"实现。
-
建议
基于基准测试,以下流程图可以帮助您决定为您的模型使用哪种后端:
%%{init: {
"theme": "neutral",
"flowchart": {
"curve": "bumpY"
}
}}%%
graph TD
A("What is your hardware?") -->|GPU| B("Are you using a small<br>batch size?")
A -->|CPU| C("Are minor performance<br>degradations acceptable?")
B -->|yes| D[onnx-O4]
B -->|no| F[float16]
C -->|yes| G[openvino-qint8]
C -->|no| H("Do you have an Intel CPU?")
H -->|yes| I[openvino]
H -->|no| J[onnx]
click D "#optimizing-onnx-models"
click F "#pytorch"
click G "#quantizing-openvino-models"
click I "#openvino"
click J "#onnx"
注意
您的实际效果可能会有所不同,您应该始终使用您的特定模型和数据来测试不同的后端,以找到最适合您用例的方案。
用户界面
此 Hugging Face Space 提供了一个用户界面,用于导出、优化和量化 ONNX 或 OpenVINO 模型