Quora 重复问题
此文件夹包含演示如何训练 SentenceTransformers 以进行信息检索的脚本。作为一个简单的示例,我们将使用 Quora 重复问题数据集。它包含超过 500,000 个句子,以及超过 400,000 个成对标注,指示两个问题是否重复。
在此数据集上训练的模型可用于挖掘重复问题,即给定大量句子(在本例中为问题),识别所有重复的句子对。由于 CrossEncoder 模型的工作方式仅适用于文本对,因此最好在使用 SentenceTransformer 模型进行初步筛选后部署它们。有关如何使用 sentence transformers 在数十万个句子中挖掘重复问题/释义的示例,请参阅 Sentence Transformer > 用法 > 释义挖掘。
初步筛选后,CrossEncoder 模型可用于将例如前 100 个候选重新排序为例如前 10 个。由于 CrossEncoder 可以在句子对的句子之间应用注意力,因此模型可以给出比 SentenceTransformer 更好的分数。
要在 Quora 重复问题数据集上训练 CrossEncoder,请参阅以下示例文件
training_quora_duplicate_questions.py:
此示例使用
BinaryCrossEntropyLoss训练 CrossEncoder 模型,使其对相同问题给出高分,对不同问题给出低分。
您也可以使用 SentenceTransformer 模型来执行此任务。有关详细信息,请参阅 Sentence Transformer > 训练示例 > Quora 重复问题。
训练
选择正确的损失函数对于微调有用的模型至关重要。BinaryCrossEntropyLoss 对于训练任何只有一个输出类(即只输出一个分数)的 CrossEncoder 模型仍然是一个非常可靠的损失。
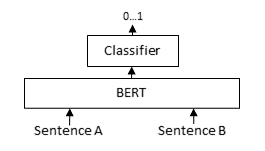
对于每个问题对,我们通过基于 BERT 的模型传递问题 A 和问题 B,之后分类器头将基于 BERT 的模型中的中间表示转换为相似度分数。通过此损失,我们应用 torch.nn.BCEWithLogitsLoss,它接受 logits(又名输出、原始预测)和黄金相似度分数(重复为 1,不重复为 0)来计算表示模型表现如何的损失。然后最小化此损失以提高模型的性能。
推理
您可以使用任何 用于重复问题检测的预训练 CrossEncoder 模型 进行推理,如下所示
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/quora-distilroberta-base')
scores = model.predict([
('What do apples consist of?', 'What are in Apple devices?'),
('How do I get good at programming?', 'How to become a good programmer?')
])
print(scores)
# [0.00056, 0.97536]