语义搜索
语义搜索旨在通过理解搜索查询和待搜索语料库的语义含义来提高搜索准确性。与只能根据词汇匹配查找文档的关键词搜索引擎不同,语义搜索在处理同义词、缩写和拼写错误时也能表现良好。
背景
语义搜索的核心思想是将语料库中的所有条目(无论是句子、段落还是文档)嵌入到一个向量空间中。在搜索时,将查询也嵌入到同一个向量空间中,然后找到语料库中最接近的嵌入。这些条目应该与查询具有高度的语义相似性。
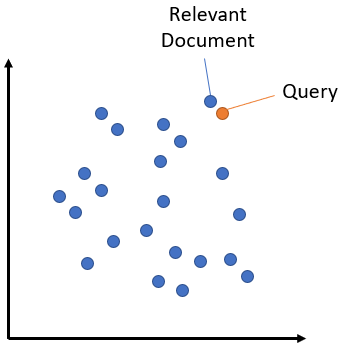
对称与非对称语义搜索
对您的设置而言,一个关键区别在于对称与非对称语义搜索。
对于对称语义搜索,您的查询和语料库中的条目长度大致相同,内容量也相似。一个例子是搜索相似问题:您的查询可以是“如何在线学习 Python?”,您希望找到像“如何在网上学习 Python?”这样的条目。对于对称任务,您可以潜在地交换查询和语料库中的条目。
相关训练示例:Quora 重复问题。
适合的模型:预训练句子嵌入模型
对于非对称语义搜索,您通常有一个简短的查询(如一个问题或一些关键词),并希望找到一个较长的段落来回答该查询。例如,查询是“什么是 Python”,您希望找到段落“Python 是一种解释型、高级和通用的编程语言。Python 的设计哲学……”。对于非对称任务,交换查询和语料库中的条目通常没有意义。
相关训练示例:MS MARCO
适合的模型:预训练 MS MARCO 模型
为您的任务类型选择正确的模型至关重要。
提示
对于非对称语义搜索,建议您使用 SentenceTransformer.encode_query 来编码您的查询,并使用 SentenceTransformer.encode_document 来编码您的语料库。
更通用的 SentenceTransformer.encode 方法在两方面与 SentenceTransformer.encode_query 和 SentenceTransformer.encode_document 不同:
如果没有提供
prompt_name或prompt,它会使用预定义的“query”或“document”提示,前提是该提示在模型的prompts字典中指定。它将
task设置为“document”。如果模型有一个Router模块,它将使用“query”或“document”任务类型来通过适当的子模块路由输入。
请注意,SentenceTransformer.encode 是最通用的方法,可用于任何任务,包括信息检索。如果模型未使用预定义的提示和/或任务类型进行训练,那么这三种方法将返回相同的嵌入。
手动实现
对于小型语料库(最多约 100 万个条目),我们可以通过手动实现来进行语义搜索,即使用 SentenceTransformer.encode_document 为语料库计算嵌入,使用 SentenceTransformer.encode_query 为我们的查询计算嵌入,然后使用 SentenceTransformer.similarity 计算语义文本相似度。
一个简单的示例,请参见 semantic_search.py
"""
This is a simple application for sentence embeddings: semantic search
We have a corpus with various sentences. Then, for a given query sentence,
we want to find the most similar sentence in this corpus.
This script outputs for various queries the top 5 most similar sentences in the corpus.
"""
import torch
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Corpus with example documents
corpus = [
"Machine learning is a field of study that gives computers the ability to learn without being explicitly programmed.",
"Deep learning is part of a broader family of machine learning methods based on artificial neural networks with representation learning.",
"Neural networks are computing systems vaguely inspired by the biological neural networks that constitute animal brains.",
"Mars rovers are robotic vehicles designed to travel on the surface of Mars to collect data and perform experiments.",
"The James Webb Space Telescope is the largest optical telescope in space, designed to conduct infrared astronomy.",
"SpaceX's Starship is designed to be a fully reusable transportation system capable of carrying humans to Mars and beyond.",
"Global warming is the long-term heating of Earth's climate system observed since the pre-industrial period due to human activities.",
"Renewable energy sources include solar, wind, hydro, and geothermal power that naturally replenish over time.",
"Carbon capture technologies aim to collect CO2 emissions before they enter the atmosphere and store them underground.",
]
# Use "convert_to_tensor=True" to keep the tensors on GPU (if available)
corpus_embeddings = embedder.encode_document(corpus, convert_to_tensor=True)
# Query sentences:
queries = [
"How do artificial neural networks work?",
"What technology is used for modern space exploration?",
"How can we address climate change challenges?",
]
# Find the closest 5 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(5, len(corpus))
for query in queries:
query_embedding = embedder.encode_query(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
similarity_scores = embedder.similarity(query_embedding, corpus_embeddings)[0]
scores, indices = torch.topk(similarity_scores, k=top_k)
print("\nQuery:", query)
print("Top 5 most similar sentences in corpus:")
for score, idx in zip(scores, indices):
print(f"(Score: {score:.4f})", corpus[idx])
"""
# Alternatively, we can also use util.semantic_search to perform cosine similarty + topk
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=5)
hits = hits[0] #Get the hits for the first query
for hit in hits:
print(corpus[hit['corpus_id']], "(Score: {:.4f})".format(hit['score']))
"""
优化实现
您可以使用 util.semantic_search 函数,而无需自己实现语义搜索。
该函数接受以下参数:
- sentence_transformers.util.semantic_search(query_embeddings: ~torch.Tensor, corpus_embeddings: ~torch.Tensor, query_chunk_size: int = 100, corpus_chunk_size: int = 500000, top_k: int = 10, score_function: ~typing.Callable[[~torch.Tensor, ~torch.Tensor], ~torch.Tensor] = <function cos_sim>) list[list[dict[str, int | float]]][source]
默认情况下,此函数在查询嵌入列表和语料库嵌入列表之间执行余弦相似度搜索。它可用于信息检索/语义搜索,适用于最多约 100 万个条目的语料库。
- 参数:
query_embeddings (
Tensor) – 一个包含查询嵌入的二维张量。可以是稀疏张量。corpus_embeddings (
Tensor) – 一个包含语料库嵌入的二维张量。可以是稀疏张量。query_chunk_size (int, 可选) – 同时处理 100 个查询。增加该值可提高速度,但需要更多内存。默认为 100。
corpus_chunk_size (int, 可选) – 一次扫描 10 万个语料库条目。增加该值可提高速度,但需要更多内存。默认为 500000。
top_k (int, 可选) – 检索前 k 个匹配条目。默认为 10。
score_function (Callable[[
Tensor,Tensor],Tensor], 可选) – 用于计算分数的函数。默认为余弦相似度。
- 返回:
一个列表,每个查询对应一个条目。每个条目是一个字典列表,包含键“corpus_id”和“score”,按余弦相似度得分降序排列。
- 返回类型:
List[List[Dict[str, Union[int, float]]]]
默认情况下,最多并行处理 100 个查询。此外,语料库被分块为最多 50 万个条目的集合。您可以增加 query_chunk_size 和 corpus_chunk_size,这会提高大型语料库的速度,但也会增加内存需求。
速度优化
为了使 util.semantic_search 方法达到最佳速度,建议将 query_embeddings 和 corpus_embeddings 放置在同一个 GPU 设备上。这会显著提升性能。此外,我们可以对语料库嵌入进行归一化,使每个语料库嵌入的长度为 1。在这种情况下,我们可以使用点积来计算分数。
corpus_embeddings = corpus_embeddings.to("cuda")
corpus_embeddings = util.normalize_embeddings(corpus_embeddings)
query_embeddings = query_embeddings.to("cuda")
query_embeddings = util.normalize_embeddings(query_embeddings)
hits = util.semantic_search(query_embeddings, corpus_embeddings, score_function=util.dot_score)
Elasticsearch
Elasticsearch 能够索引密集向量并将其用于文档评分。我们可以轻松地索引嵌入向量,将其他数据与我们的向量一起存储,最重要的是,使用嵌入上的近似最近邻搜索(HNSW,另见下文)高效地检索相关条目。
有关详细信息,请参阅 semantic_search_quora_elasticsearch.py。
OpenSearch
OpenSearch 是一个社区驱动的开源搜索引擎,支持向量搜索功能。它允许您索引密集向量,并使用近似最近邻算法执行高效的相似性搜索。OpenSearch 可用于实现传统的基于关键字的搜索(BM25)和语义搜索,从而可以比较和组合这两种方法。
有关实现示例,请参阅 semantic_search_nq_opensearch.py,该示例展示了如何将 OpenSearch 与自然问题数据集结合使用,演示了语义搜索和 BM25 搜索功能。
近似最近邻
如果使用精确的最近邻搜索(如 util.semantic_search 所使用的),搜索包含数百万嵌入的大型语料库可能会非常耗时。
在这种情况下,近似最近邻(ANN)会很有帮助。ANN 将数据划分为相似嵌入的较小部分。可以高效地搜索此索引,并在毫秒内检索出相似度最高的嵌入(最近邻),即使您有数百万个向量。然而,结果不一定是精确的。可能会漏掉一些相似度很高的向量。
对于所有 ANN 方法,通常有一个或多个参数需要调整,以决定召回率与速度之间的权衡。如果您想要最快的速度,您有很大概率会错过一些匹配项。如果您想要高召回率,搜索速度会下降。
三个流行的近似最近邻库是 Annoy、FAISS 和 hnswlib。
示例
检索与重排
对于复杂的语义搜索场景,建议采用两阶段的“检索与重排”流程: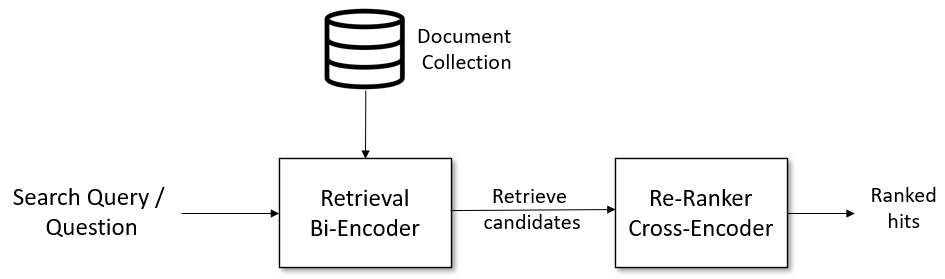
更多详情,请参见检索与重排。
示例
我们列出了一些常见的用例
相似问题检索
semantic_search_quora_pytorch.py [ Colab 版本 ] 展示了一个基于 Quora 重复问题数据集的示例。用户可以输入一个问题,代码会使用 util.semantic_search 从数据集中检索最相似的问题。我们使用的模型是 distilbert-multilingual-nli-stsb-quora-ranking,该模型经过训练用于识别相似问题,并支持 50 多种语言。因此,用户可以用 50 多种语言中的任何一种输入问题。这是一个对称搜索任务,因为搜索查询的长度和内容与语料库中的问题相同。
相似出版物检索
semantic_search_publications.py [ Colab 版本 ] 展示了一个如何查找相似科学出版物的示例。我们使用在 EMNLP 2016 - 2018 会议上发表的所有出版物作为语料库。作为搜索查询,我们输入较新出版物的标题和摘要,并从我们的语料库中查找相关的出版物。我们使用 SPECTER 模型。这是一个对称搜索任务,因为语料库中的论文由标题和摘要组成,我们搜索的也是标题和摘要。
问答检索
semantic_search_wikipedia_qa.py [ Colab 版本 ]:此示例使用在自然问题数据集上训练的模型。该数据集包含约 10 万个真实的谷歌搜索查询,以及一个提供答案的维基百科注释段落。这是一个非对称搜索任务的例子。作为语料库,我们使用较小的简单英语维基百科,以便轻松地装入内存。
retrieve_rerank_simple_wikipedia.ipynb [ Colab 版本 ]:此脚本使用检索与重排策略,是非对称搜索任务的一个例子。我们将所有维基百科文章分割成段落,并用双编码器对其进行编码。当输入新的查询/问题时,它由同一个双编码器编码,并检索余弦相似度最高的段落。接下来,检索到的候选段落由交叉编码器重排器评分,并将交叉编码器得分最高的 5 个段落呈现给用户。我们使用的模型是在 MS Marco 段落重排数据集上训练的,该数据集包含约 50 万个来自必应搜索的真实查询。