无监督学习
本页面包含用于学习句子嵌入的无监督学习方法集合。这些方法的共同点是它们不需要带标签的训练数据。相反,它们可以仅从文本本身学习具有语义意义的句子嵌入。
注意
无监督学习方法仍然是一个活跃的研究领域,在许多情况下,与我们训练数据集合中提供的使用训练对的模型相比,它们的性能相当差。一个更好的方法是域适应,您可以在目标域上结合无监督学习和现有的带标签数据。这应该会在您的特定语料库上获得最佳性能。
TSDAE
在我们的工作TSDAE (基于 Transformer 的去噪自编码器)中,我们提出了一种基于去噪自编码器的无监督句子嵌入学习方法
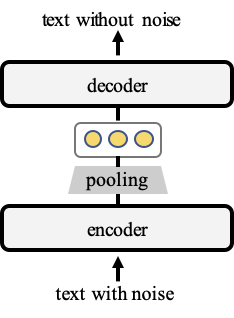
我们向输入文本添加噪声,在我们的例子中,我们删除了文本中大约 60% 的单词。编码器将此输入映射到固定大小的句子嵌入。然后解码器尝试重新创建没有噪声的原始文本。稍后,我们使用编码器作为句子嵌入方法。
有关更多信息和训练示例,请参阅TSDAE。
SimCSE
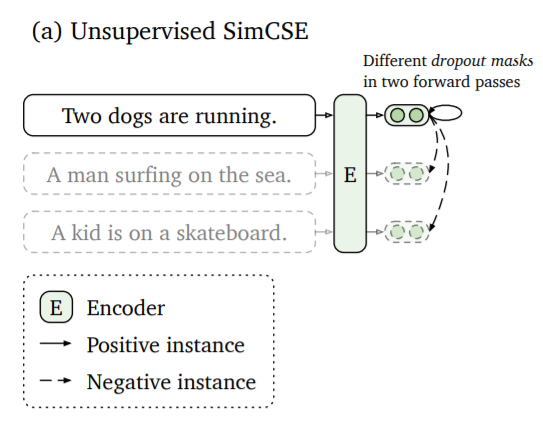
Gao 等人在SimCSE:简单的对比学习句子嵌入中提出了一种方法,该方法将相同的句子两次传递给句子嵌入编码器。由于 dropout,它将在向量空间中以略微不同的位置进行编码。
这两个嵌入之间的距离将被最小化,而与同一批次中其他句子的其他嵌入之间的距离将被最大化。
有关更多信息和训练示例,请参阅SimCSE。
CT
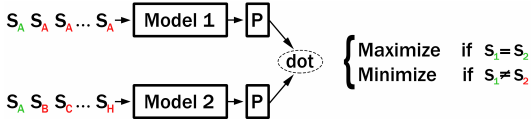
Carlsson 等人在使用对比张力 (CT) 进行语义重调中提出了一种无监督方法,该方法使用两个模型:如果将相同的句子传递给 Model1 和 Model2,则各自的句子嵌入应获得较高的点分数。如果传递不同的句子,则句子嵌入应获得较低的分数。
有关更多信息和训练示例,请参阅CT。
CT(批内负采样)
Carlsson 等人的 CT 方法将句子对提供给两个模型。这可以通过使用批内负采样来改进:Model1 和 Model2 都编码相同的句子集。我们最大化匹配索引的分数(即 Model1(S_i) 和 Model2(S_i)),同时最小化不同索引的分数(即 Model1(S_i) 和 Model2(S_j),其中 i != j)。
有关更多信息和训练示例,请参阅CT_In-Batch_Negatives。
掩码语言模型(MLM)
BERT 表明掩码语言模型(MLM)是一种强大的预训练方法。建议在微调之前,先在您的领域的大型数据集上运行 MLM。有关更多信息和训练示例,请参阅MLM。
GenQ
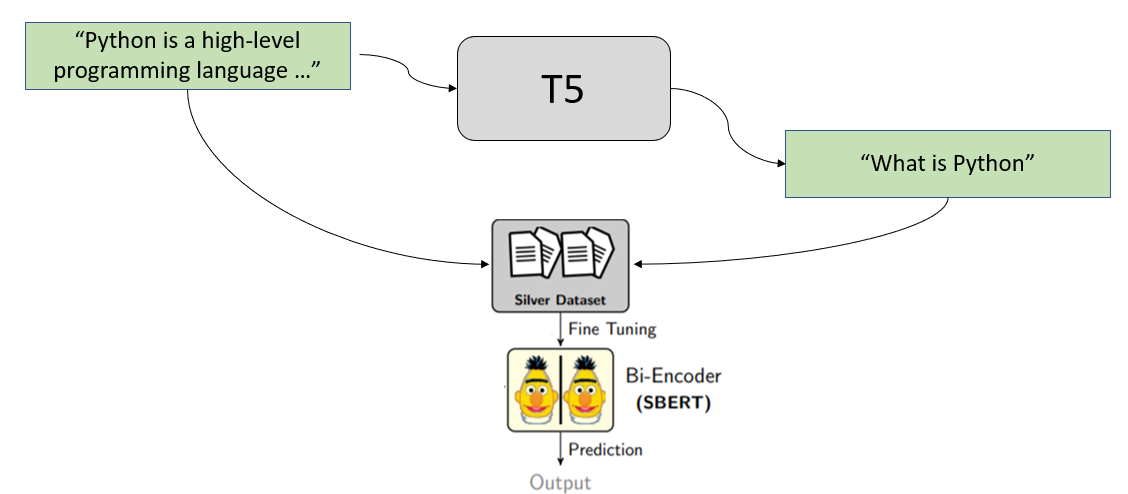
在我们的论文BEIR:信息检索模型零样本评估的异构基准中,我们提出了一种通过为给定段落生成查询来学习语义搜索方法。此方法已在GPL:用于密集检索无监督域适应的生成伪标签中得到改进。
我们将集合中的所有段落通过训练好的 T5 模型,该模型生成用户潜在的查询。然后我们使用这些(查询,段落)对来训练 SentenceTransformer 模型。
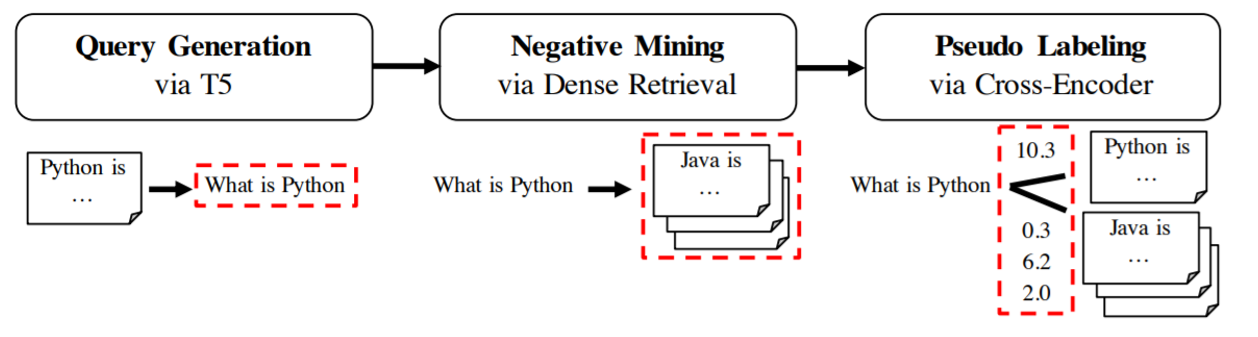
GPL
在GPL:用于密集检索无监督域适应的生成伪标签中,我们展示了 GenQ 的改进版本,它将生成与负挖掘和使用交叉编码器的伪标签结合起来。它显著改进了结果。有关更多信息,请参阅域适应。
性能比较
在我们的论文TSDAE中,我们比较了句子嵌入任务的方法,在GPL中,我们比较了它们在语义搜索任务中的表现(给定一个查询,找到相关段落)。虽然无监督方法在句子嵌入任务中取得了可接受的性能,但在语义搜索任务中表现不佳。