SimCSE
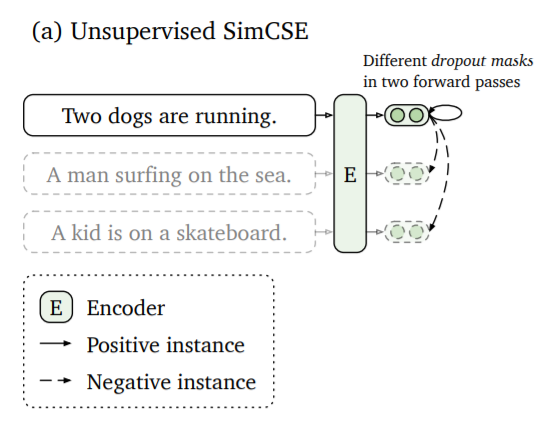
Gao 等人在 SimCSE 中提出了一种无需训练数据即可训练句子嵌入的简单方法。
其思想是对同一个句子进行两次编码。由于 Transformer 模型中使用了 dropout,两个句子嵌入的位置会略有不同。这两个嵌入之间的距离将被最小化,而与同一批次中其他句子的嵌入(它们作为负样本)的距离将被最大化。
在 SentenceTransformers 中使用
SentenceTransformers 实现了 MultipleNegativesRankingLoss,这使得使用 SimCSE 进行训练变得非常简单。
from sentence_transformers import SentenceTransformer, InputExample
from sentence_transformers import models, losses
from torch.utils.data import DataLoader
# Define your sentence transformer model using CLS pooling
model_name = "distilroberta-base"
word_embedding_model = models.Transformer(model_name, max_seq_length=32)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# Define a list with sentences (1k - 100k sentences)
train_sentences = [
"Your set of sentences",
"Model will automatically add the noise",
"And re-construct it",
"You should provide at least 1k sentences",
]
# Convert train sentences to sentence pairs
train_data = [InputExample(texts=[s, s]) for s in train_sentences]
# DataLoader to batch your data
train_dataloader = DataLoader(train_data, batch_size=128, shuffle=True)
# Use the denoising auto-encoder loss
train_loss = losses.MultipleNegativesRankingLoss(model)
# Call the fit method
model.fit(
train_objectives=[(train_dataloader, train_loss)], epochs=1, show_progress_bar=True
)
model.save("output/simcse-model")
从句子文件进行 SimCSE 训练
train_simcse_from_file.py 从提供的文本文件中加载句子。该文本文件应为每行一个句子。
SimCSE 将使用这些句子进行训练。每 500 步会将检查点存储到输出文件夹中。
训练示例
train_askubuntu_simcse.py - 展示了如何在 AskUbuntu Questions 数据集上使用 SimCSE 进行训练的示例。
train_stsb_simcse.py - 此脚本使用 100 万个句子,并在 STSbenchmark 数据集上评估 SimCSE。
消融研究
我们使用在 TSDAE 论文中提出的评估设置。
使用平均池化,max_seq_length=32,batch_size=128
| 基础模型 | AskUbuntu 测试性能 (MAP) |
|---|---|
| distilbert-base-uncased | 53.59 |
| bert-base-uncased | 54.89 |
| distilroberta-base | 56.16 |
| roberta-base | 55.89 |
使用平均池化,max_seq_length=32,以及 distilroberta-base 模型。
| 批次大小 | AskUbuntu 测试性能 (MAP) |
|---|---|
| 128 | 56.16 |
| 256 | 56.63 |
| 512 | 56.69 |
使用 max_seq_length=32,distilroberta-base 模型,以及 512 批次大小。
| 池化模式 | AskUbuntu 测试性能 (MAP) |
|---|---|
| 平均池化 | 56.69 |
| CLS 池化 | 56.56 |
| 最大池化 | 52.91 |
注意: 这是在 sentence-transformers 中对 SimCSE 的重新实现。有关官方 CT 代码,请参见: princeton-nlp/SimCSE